Sitevision – förbättra söket med Nutch
Ett av Sveriges mest populära CMS verktyg är Sitevision, som används kanske främst av stora statliga myndigheter och kommuner. Valet att använda sig av Sitevision hos dessa myndigheter och kommuner är nog att det är väldigt enkelt för redaktörer och sidansvariga att använda och att underhålla informationen på sina sidor. Detta i en miljö där kanske den webbtekniska kunskapen inte är på samma nivå som hos ett större teknikföretag.
Men medans vi hyllar det enkla användargränssnittet så önskar vi att det gick att bygga bättre sökfunktionalitet. Visst kan du söka i en webbsajt, det går även att söka på andra webbsajter, om du har satt upp flera webbsajter inom samma system. Men om du vill söka i en webbsajt eller databas som finns någon annanstans då går det inte. Men detta är på väg att ändras. Sitevision introducerar snart webbkravlaren Nutch, en mycket avancerad webcrawler som bygger på Hadoop, som i sin tur är del av ett ramverk för att hantera mycket stora mängder data. Nutch tillsammans med Solr kommer att lyfta Sitevisions sök till nya höjder.
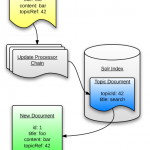
Nedan är ett schema för hur en sajt-indexering skulle kunna se ut:
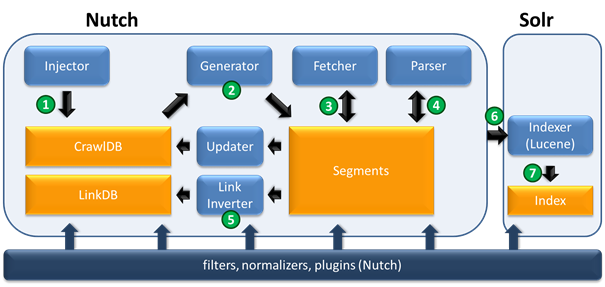
1. ”Injector” tar alla webbadresser i nutch.txt filen och lägger till dem i ”CrawlDB”. Som är en central del av Nutch. CrawlDB innehåller information om alla kända webbadresser (hämta schema, hämta status, metadata, …).
2. Baserat på data från CrawlDB skapar ”Generator” en lista på vad som ska hämtas och placerar det i en nyskapad segment katalog.
3. Nästa steg, ”Fetcher” får de adresser som ska hämtas från listan och skriver det tillbaka till segment katalogen. Detta steg är vanligtvis den mest tidskrävande delen.
4. Nu kan ”Parser” behandla innehållet i varje webbsida och exempelvis utelämnar alla html-taggar. Om denna hämtning (crawl) är en uppdatering eller en utökning av en redan tidigare hämtning (t.ex. djup 3), skulle ”Updater” lägga till nya data till CrawlDB som ett nästa steg.
5. Före indexering måste alla länkar inverteras av ”Link Inverter”, som tar hänsyn till att inte antalet utgående länkar på en webbsida är av intresse, utan snarare antalet inkommande länkar. Detta är ganska likt hur Google Pagerank fungerar och är viktig för scoring funktion. De inverterade länkarna sparas i “Linkdb”.
6-7. Med hjälp av data från alla möjliga källor (CrawlDB, LinkDB och segment), skapar Indexer ett index och sparar det i Solr katalogen. För indexering, används det populära Lucene biblioteket. Nu kan användaren söka efter information om genomsökta webbsidor via Solr.
Funktionalitet som följer med Nutch:
- Indexering av externa källor
- Automatisk kategorisering
- Metadata
- Textanalys
- Utökad funktionalitet enkelt med plugins
Nyttiga länkar:
- https://en.wikipedia.org/wiki/Apache_Nutch
- http://wiki.apache.org/nutch/
- http://nutch.apache.org/
- http://www.sitevision.se/vara-produkter/sitevision.html