Experimenting with Open Source Web Crawlers
Whether you want to do market research or gather financial risk information or just get news about your favorite footballer from various news site, web scraping has many uses.
In my quest to learn know more about web crawling and scraping , I decided to test couple of Open Source Web Crawlers which were not only easily available but quite powerful as well. In this article I am mostly going to cover their basic features and how easy they are to start with.
If you are like one of those persons who likes to quickly get started while learning something, I would suggest that you try OpenWebSpider first.
It is a simple web browser based open source crawler and search engine which is simple to install and use and is very good for those who are trying to get acquainted to web crawling . It stores webpages in MySql or MongoDb. I used MySql for my testing purpose. You can follow the steps here to install it. It’s pretty simple and basic.
So, once you have installed everything , you just need to open a web-browser at http://127.0.0.1:9999/ and you are ready to crawl and search. Just check your database settings, type the Url of the site you want to crawl and within couple of minutes, you have all the data you need. You can even search it going to the search tab and typing in your query. Whoa! That was quick and compact and needless to say you don’t need any programming skills to crawl it.
If you are trying to create an off-line copy of your data or your very own mini Wikipedia, I think go for this as it’s the easiest way to do it.
Following are some screen shots:
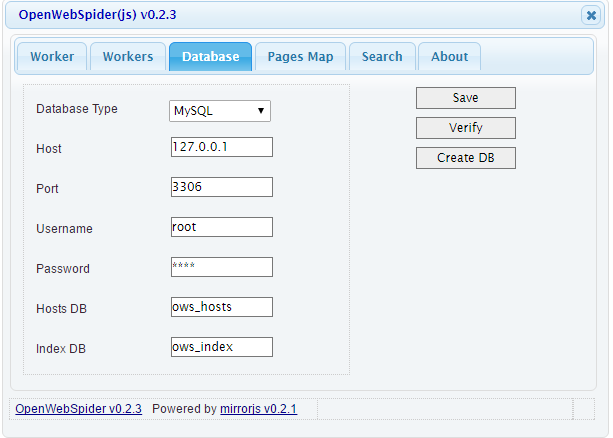
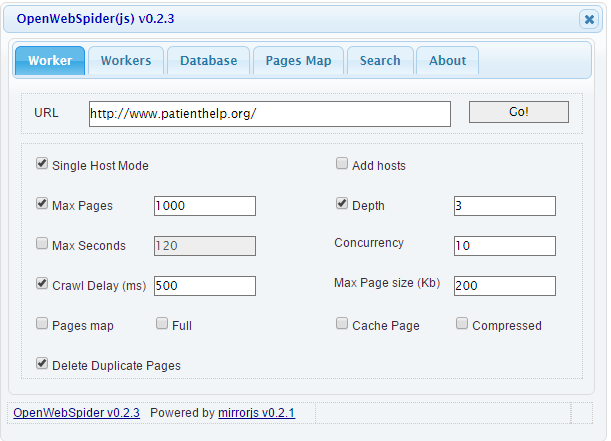
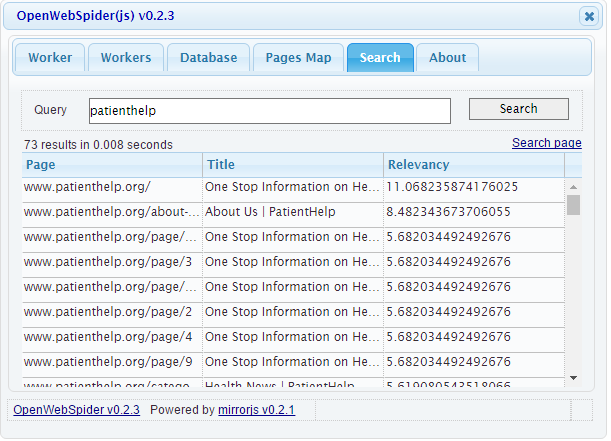
You can also see the this Search engine demo here, before actually getting started.
Ok, after getting my hands on into web crawling, I was curious to do more sophisticated stuff like extracting topics from a web site where I do not have any RSS feed or API. Extracting this structured data could be quite important to many business scenarios where you are trying to follow competitor’s product news or gather data for business intelligence. I decided to use Scrapy for this experiment.
The good thing about Scrapy is that it is not only fast and simple, but very extensible as well. While installing it on my windows environment, I had few hiccups mainly because of the different compatible version of python but in the end, once you get it, it’s very simple(Isn’t that how you feel anyways , once things works ? Anyways, forget it! :D). Follow these links, if you are having trouble installing Scrapy like me:
https://github.com/scrapy/scrapy/wiki/How-to-Install-Scrapy-0.14-in-a-64-bit-Windows-7-Environment
http://doc.scrapy.org/en/latest/intro/install.html#intro-install
After installing, you need to create a Scrapy project. Since we are doing more customized stuff than just crawling the entire website, this requires more effort and knowledge of programming skills and sometime browser tools to understand the HTML DOM. You can follow this link to get started with you first Scrapy project .Once you have crawled the data that you need, it would be interesting to feed this data into a search engine. I have also been looking for open source web crawlers for Elastic Search and this looked like the perfect opportunity. Scrapy provides integration with Elastic Search out of the box , which is awesome. You just need to install the Elastic Search module for Scrapy(of course Elastic Search should be running somewhere) and configure the Item Pipeline for Scrapy. Follow this link for the step by step guide. Once done, you have the fully integrated crawler and search system!
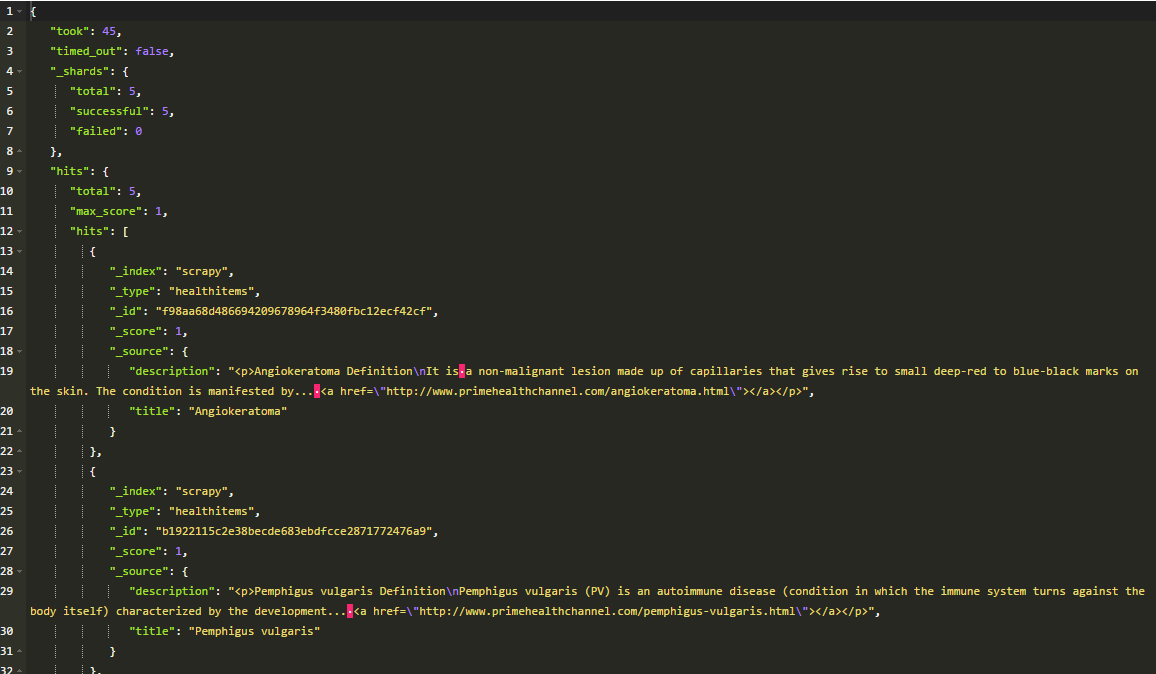
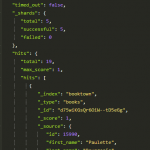
I crawled http://primehealthchannel.com and created an index named “healthitems” in Scrapy.
To search the elastic search index, I am using Chrome extension Sense to send queries to Elastic Search, and this is how it looks
GET /scrapy/healthitems/_search
I hope you had fun reading this and now wants to try some of your own cool ideas . Do let us know how you used it and which crawler you like the most!
Related Posts
 Elasticsearch: Indexing SQL databases. The easy way.
Elasticsearch: Indexing SQL databases. The easy way. Dynamic search ranking using Elasticsearch, Neo4j and Piwik
Dynamic search ranking using Elasticsearch, Neo4j and Piwik How to develop Logstash configuration files
How to develop Logstash configuration files Tech choices for the seasonal recipes app: A skeleton architecture for working with search relevancy
Tech choices for the seasonal recipes app: A skeleton architecture for working with search relevancy Analyzing web server logs with Elasticsearch in the cloud
Analyzing web server logs with Elasticsearch in the cloud Idea: Your life searchable through Norch – NOde seaRCH, IFTTT and Google Drive
Idea: Your life searchable through Norch – NOde seaRCH, IFTTT and Google Drive

