Elasticsearch: Indexing SQL databases. The easy way.
Elasticsearch is a great search engine, flexible, fast and fun. So how can I get started with it? This post will go through how to get contents from a SQL database into Elasticsearch.
Rivers are deprecated since Elasticsearch version 1.5. Read this official statement https://www.elastic.co/blog/deprecating_rivers. However, river-jdbc lives on as elasticsearch JDBC importer. Some day this post will be updated with instructions for using JDBC importer mode.
Elasticsearch has a set of pluggable services called rivers. A river runs inside an Elasticsearch node, and imports content into the index. There are rivers for twitter, redis, files, and of course, SQL databases. The river-jdbc plugin connects to SQL databases using JDBC adapters. In this post we will use PostgreSQL, since it is freely available, and populate it with some contents that also are freely available.
So let’s get started
- Download and install Elasticsearch
- Start elasticsearch by running bin/elasticsearch from the installation folder
- Install the river-jdbc plugin for Elasticsearch version 1.00RC
1./bin/plugin -install river-jdbc -url <em><a href="http://bit.ly/1dKqNJy">http://bit.ly/1dKqNJy</a> </em> - Download the PostgreSQL JDBC jar file and copy into the plugins/river-jdbc folder. You should probably get the latest version which is for JDBC 41
- Install PostgreSQL http://www.postgresql.org/download/
- Import the booktown database. Download the sql file from booktown database
- Restart Elasticsearch
- Start PostgreSQL
By this time you should have Elasticsearch and PostgreSQL running, and river-jdbc ready to use.
Now we need to put some contents into the database, using psql, the PostgreSQL command line tool.
|
1 |
psql -U postgres -f booktown.sql |
To execute commands to Elasticsearch we will use an online service which functions as a mixture of Gist, the code snippet sharing service and Sense, a Google Chrome plugin developer console for Elasticsearch. The service is hosted by http://qbox.io, who provide hosted Elasticsearch services.
Check that everything was correctly installed by opening a browser to http://sense.qbox.io/gist/8361346733fceefd7f364f0ae1ebe7efa856779e
Select the top most line in the left-hand pane, press CTRL+Enter on your keyboard. You may also click on the little triangle that appears to the right, if you are more of a mouse click kind of person.
You should now see a status message, showing the version of Elasticsearch, node name and such.
Now let’s stop fiddling around the porridge and create a river for our database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
curl -XPUT "http://localhost:9200/_river/mybooks/_meta" -d' { "type": "jdbc", "jdbc": { "driver": "org.postgresql.Driver", "url": "jdbc:postgresql://localhost:5432/booktown", "user": "postgres", "password": "postgres", "index": "booktown", "type": "books", "sql": "select * from authors" } }' |
This will create a “one-shot” river that connects to PostgreSQL on Elasticsearch startup, and pulls the contents from the authors table into the booktown index. The index parameter controls what index the data will be put into, and the type parameter decides the type in the Elasticsearch index. To verify the river was correctly uploaded execute
|
1 |
GET /_river/mybooks/_meta |
Restart Elasticsearch, and watch the log for status messages from river-jdbc. Connection problems, SQL errors or other problems should appear in the log . If everything went OK, you should see something like …SimpleRiverMouth] bulk [1] success [19 items]
Time has come to check out what we got.
|
1 |
GET /booktown/_search |
You should now see all the contents from the authors table. The number of items reported under “hits” -> “total” are the same as what we just saw in the log: 19.
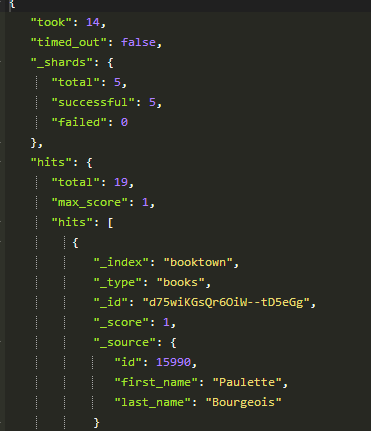
But looking more closely at the data, we can see that the _id field has been auto-assigned with some random values. This means that the next time we run the river, all the contents will be re-added.
Luckily, river-jdbc support some specially labeled fields, that let us control how the contents should be indexed.
Reading up on the docs, we change the SQL definition in our river to
|
1 2 |
select id as _id, first_name, last_name from authors |
We need to start afresh and scrap the index we just created:
|
1 |
DELETE /booktown |
Restart Elasticsearch. Now you should see a meaningful id in your data.
At this time we could start toying around with queries, mappings and analyzers. But, that’s not much fun with this little content. We need to join in some tables and get some more interesting data. We can join in the books table, and get all the books for all authors.
|
1 2 3 |
SELECT authors.id as _id, authors.last_name, authors.first_name, books.id, books.title, books.subject_id FROM public.authors left join public.books on books.author_id = authors.id |
Delete the index, restart Elasticsearch and examine the data. Now you see that we only get one book per author. Executing the SQL statement in pgadmin returns 22 rows, while in Elasticsearch we get 19. This is on account of the _id field, on each attempt to index an existing record with the same _id as a new one, it will be overwritten.
River-jdbc supports Structured objects, which allows us to create arbitrarily structured JSON documents simply by using SQL aliases. The _id column is used for identity, structured objects will be appended to existing data. This is perhaps best shown by an example:
|
1 2 3 4 |
SELECT authors.id as _id, authors.last_name, authors.first_name, books.id as \"Books.id\", books.title as \"Books.title\", books.subject_id as \"Books.subject_id\" FROM public.authors left join public.books on books.author_id = authors.id order by authors.id |
Again, delete the index, restart Elasticsearch, wait a few seconds before you search, and you will find structured data in the search results.
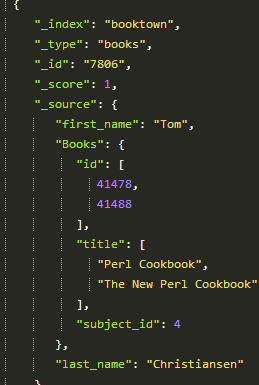
Now we have seen that it is quite easy to get data into Elasticsearch using river-jdbc. We have also seen how it can handle updates. That gets us quite far. Unfortunately, it doesn’t handle deletions. If a record is deleted from the database, it will not automatically be deleted from the index. There have been some attempts to create support for it, but in the latest release it has been completely dropped.
This is due to the river plugin system having some serious problems, and it will perhaps be deprecated some time after the 1.0 release, at least not actively promoted as “the way”. (see the “semi-offical statement” at Linkedin Elasticsearch group). While it is extremely easy to use rivers to get data, there are a lot of problems in having a data integration process running in the same space as Elasticsearch itself. Architecturally, it is perhaps more correct to leave the search engine to itself, and build integrations systems on the side.
Among the recommended alternatives are:
>Use an ETL tool like Talend
>Create your own script
>Edit the source application to send updates to Elasticsearch
Jörg Prante, who is the man behind river-jdbc, recently started creating a replacement called Gatherer.
It is a gathering framework plugin for fetching and indexing data to Elasticsearch, with scalable components.
Anyway, we have data in our index! Rivers may have their problems when used on a large scale, but you would be hard pressed to find anything easier to get started with. Getting data into the index easily is essential when exploring ideas and concepts, creating POCs or just fooling around.
This post has run out of space, but perhaps we can look at some interesting queries next time?
Related Posts
 Idea: Your life searchable through Norch – NOde seaRCH, IFTTT and Google Drive
Idea: Your life searchable through Norch – NOde seaRCH, IFTTT and Google Drive Solr: Indexing SQL databases made easier!
Solr: Indexing SQL databases made easier! Dynamic search ranking using Elasticsearch, Neo4j and Piwik
Dynamic search ranking using Elasticsearch, Neo4j and Piwik Elasticsearch smashtime
Elasticsearch smashtime Norch- a search engine for node.js
Norch- a search engine for node.js How to “spy” the data in a custom pipeline extensibility stage with FS4SP
How to “spy” the data in a custom pipeline extensibility stage with FS4SP


[...] Comperio is a search solutions company, and we are genuinely enthusiastic about usable, engaging and profitable search. This is our blog! [...]
Not handling deletions seems like a rather serious problem to me!
Deletions!? Aren’t they a blast from the past?
On a more serious note: If you have only a modest amount of data, you can recreate your index on a schedule. You may use index templates and aliases to make sure there is no downtime in the process. In my experience, indexing is blazing fast. But again, you may not want do to it with really big data.
Great blog post!
Make sure to use latest version of both Elasticsearch and the river-jdbc plugin as the “index”-parameter in plugin version 2.3.1 is not working as intended.
I would +1 for this option which is to me the best way to do it if it’s possible:
Edit the source application to send updates to Elasticsearch
You gain:
* real time indexing (so NRT search)
* no need to read the database again for indexing (which can cost a lot)
* able to generate complex objects (think of collections of collections of …)
* When you persist a document to the database it’s often already in memory. Pushing it to elasticsearch won’t cost you much (CPU time).
My 2 cents
Nice blog post BTW.
[...] Elasticsearch is a great search engine, flexible, fast and fun. So how can I get started with it? This post will go through how to get contents from a SQL database into Elasticsearch. [...]
Great! You have written nice. But I think, you missed one point. Why should we use elasticsearch for relational database? We already have hibernate and spring etc great and old technologies. People are used to them. Why they should migrate from hibernate and spring etc technologies to elasticsearch river?
Can you please elaborate following word?
flexible, fast and fun?
Hi Vijay.
We elaborate on the reasons why we think Elasticsearch is a flexible, fast and fun search engine in some other blog posts already on this site.
I am sure we will publish more posts on Elasticsearch.
Perhaps it would be a good idea to compare traditional SQL databases with Elasticsearch, since it is both a NoSQL database and a search engine.
So just keep watching us :)
Hi, good post!
I were managed to run it successfully once.
But right now, constantly getting this error: org.elasticsearch.common.settings.NoClassSettingsException: Failed to load class with value
Do you know how to troubleshoot this issue?
[2014-05-31 21:45:56,180][WARN ][bootstrap ] jvm uses the client vm, make sure to run
javawith the server vm for best performance by adding-serverto the command line[2014-05-31 21:45:56,465][INFO ][node ] [Volstagg] version[1.1.2], pid[7618], build[e511f7b/2014-05-22T12:27:39Z]
[2014-05-31 21:45:56,465][INFO ][node ] [Volstagg] initializing …
[2014-05-31 21:45:56,488][INFO ][plugins ] [Volstagg] loaded [support-1.1.0.7-1720683, jdbc-1.1.0.2-b016a06], sites []
[2014-05-31 21:46:02,530][INFO ][node ] [Volstagg] initialized
[2014-05-31 21:46:02,530][INFO ][node ] [Volstagg] starting …
[2014-05-31 21:46:02,689][INFO ][transport ] [Volstagg] bound_address {inet[/0:0:0:0:0:0:0:0:9300]}, publish_address {inet[/10.90.221.178:9300]}
[2014-05-31 21:46:05,829][INFO ][cluster.service ] [Volstagg] new_master [Volstagg][Is382euiQTCigiSziR4OeA][ip-10-90-221-178][inet[/10.90.221.178:9300]], reason: zen-disco-join (elected_as_master)
[2014-05-31 21:46:05,865][INFO ][discovery ] [Volstagg] elasticsearch/Is382euiQTCigiSziR4OeA
[2014-05-31 21:46:05,984][INFO ][http ] [Volstagg] bound_address {inet[/0:0:0:0:0:0:0:0:9200]}, publish_address {inet[/10.90.221.178:9200]}
[2014-05-31 21:46:07,351][INFO ][gateway ] [Volstagg] recovered [1] indices into cluster_state
[2014-05-31 21:46:07,353][INFO ][node ] [Volstagg] started
[2014-05-31 21:46:07,922][WARN ][river ] [Volstagg] failed to create river [orders][ad_jdbc_river]
org.elasticsearch.common.settings.NoClassSettingsException: Failed to load class with value [orders]
Hi Konstantin!
Nice to hear that you tried it out. I haven’t seen that error before, perhaps you could check out the river-jdbc issues . Also double check that you got the jdbc driver in the plugin/river-jdbc folder.
Aren’t rivers soon to be depreciated from Elastic Search?
Could it be better to use the SQL Logs and LogStash?
I’m currently evaluating a number of options for a hotel booking agency project I’m working on.
Hi Ben, Yes you’re right, the river plugins will be moved out of Elasticsearch some time in the future. As for river-jdbc, it now can run in “feeder mode” in it’s own JVM outside of Elasticsearch.
For the best option, scroll up to David Pilato’s comment above:
“Edit the source application to send updates to Elasticsearch”
Hi,
I want to know that how to search partial word from database using analyzer ?
I am trying but I am not getting it.
I am getting error.
I am adding setting block with analyzer while creating the index from database.
I have asked question http://stackoverflow.com/questions/27441986/create-analyzer-while-creating-index-with-database-table-in-elasticsearch
Will you guide me ?
Blog is good but please provide with instructions for using JDBC importer mode. need urgently
Another app to sync data from SQL databases: https://github.com/takemoa/sqldb2es