Dynamic search ranking using Elasticsearch, Neo4j and Piwik
Getting the correct result at the top of your search results isn’t easy. Anyone working within search quickly realizes this. Tuning the underlying ranking model is a job that just doesn’t end. There is an entire profession about search engine optimization, making sure your site gets as high as possible on Google (and Bing, I guess). If it is not the top result on Google, it is somehow your fault and not Google’s.
Nobody optimizes for an internal enterprise search solution
If your document is not the top result in the internal search solution it is somehow the search engine’s fault, not yours. There is no link cardinality on a file system. All the metadata is wrong and the document your user is trying to find doesn’t even contain the words the user remembers it to contain; the end result being that the target document is not found. As a result of this, trust in the enterprise search diminishes and soon you are left without users. Let’s see how we can use Piwik, neo4j and Elasticsearch to remedy this. (Yes, you can use Solr if you want).
This post is made up of three parts. First I’ll talk about gathering the data necessary. Then we’ll tackle getting the ‘right’ documents at the top of your search and lastly we’ll see if we can expand documents with words your users recalls them by, but are not part of the documents themselves. The journey will be based on the work performed on Comperio’s internal search, at the moment implemented on an old Fast ESP installation.
Gathering data
First you need to know what your users are searching for and what they end up clicking on. We use Piwik, an open source web analytics platform, for this. Seeing the searches, modifications to the searches and if they ended up clicking on anything that they thought was exciting. For a while we only used this for statistics since Piwik offered better insight than the built in query statistics in Fast ESP. Here is an example of one search session:
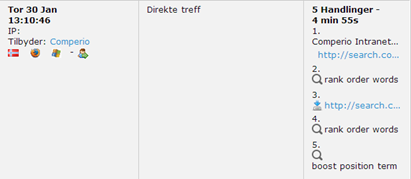
We see a user entering the site, querying ‘rank order words’ and clicking on a document. Then the same search is executed again. It is reasonable to conclude the clicked document did not contain the wanted information. Lastly ‘boost position term’ is searched. Sadly the session does not end with a click so I guess our search couldn’t deliver. :( [1]
In their current form, the statistics aren’t very useful. But what were to happen if we took these chains of activities and created a graph? We used neo4j for this. A small Java program was written to download the Piwik-history as an XML-file and insert it into a newly created neo4j database.
The nodes are either the start of a session, a search or a document. They are linked by relationships such as CLICKED, SEARCHED, RETURNED_FROM. Since a neo4j database isn’t very screen shot friendly, here is a part of the graph as rendered by Gephi:

We see someone looking for help with Chinese query suggestions. S361 marks the beginning of this session and the first search term was ‘chinese’. They then clicked a link for an internal mail archive before refining their search to ‘chinese als’ and so forth. Links that show when a user back tracked are not shown. That was an isolated little island. The more central documents and search terms at your company will create bigger webs.
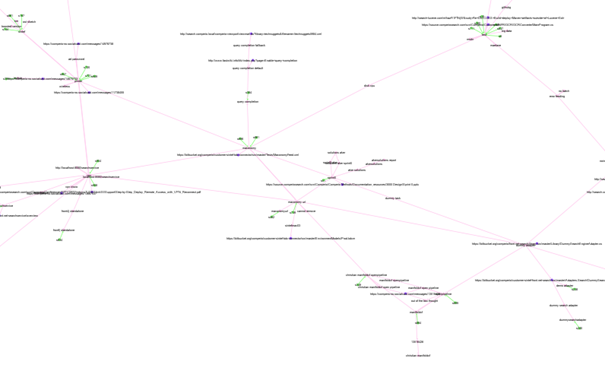
Seeing your search history organized like this should give an urge to dive in and explore. It is really interesting, fun and recommended!
Finding popular documents
The simplest way of finding the popular documents is to track search term -> clicks directly. It is also the most common way of doing it. That wouldn’t utilize our fancy new graph now, would it? Since we can do queries against the database let’s get all search sessions of 8 or less actions that resulted in a click on document X:
![]()
Page Break(Small disclaimer: As my neo4j skills are very rudimentary there might be more efficient ways of doing this.)
Now we iterate over all sessions and give a score to each search term. The closer it is to the clicked document, the higher score it gets. Sum the score across all sessions. After doing that you get a score indicating how ‘close’ a search term is to any document. This is example data for the single-word search term ‘vpn’:

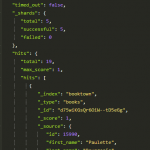
When the score passes a threshold we add the search-document pair to an Elasticsearch index. For every search executed at our search we first check Elasticsearch to see if the term is boosted. For ‘vpn’ the search logs state

We can see how three documents are boosted for ‘vpn’. (By choice we only boost the top three). Using Fast ESP we wrap the original query with boosts for those specific documents.
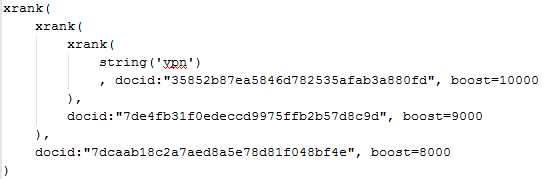
In FAST ESP, as well as in Sharepoint Search 2013 the beloved xrank-operator is your friend. In a Lucene based search application use boost queries for this.
The search result returns the popular hits (only one shown here) at the top

The ugly star and cheesy feedback is me trying to tell the users rather bluntly that things happened behind the scene and that their actions will affect future searches. Currently there is no way of giving negative feedback to say ‘no, this is actually not a good hit’. Oh well.
As a bonus all terms that results in boosted documents are, as far as we know, smart things to search for and free of spelling errors. Therefor all such terms are added to a second Elasticsearch index we base our query completion on. (As a side note – if misspelled terms appear often enough to overcome the threshold for them to be taken into account, they could be part of your organization’s tribal language. If the users choose to spell the term “definately” so often that it “makes the cut” then the system should adapt to that. )
Expanding documents to increase recall
Often a user thinks of one document and searches for what, to them, identifies the document. That term might or might not be present in the document itself. If it doesn’t the document is not returned and the user becomes sad. Hopefully they alter their search and continue to look. Should they end up at their document we have the tools needed to remedy the situation. Here is a concrete example:
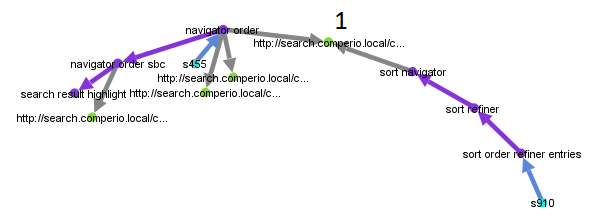
Here we can see that the node marked 1 might be tagged with ‘sort order refiner entries’ or at least ‘refiner’, a term used twice when trying to find this document. (As an interesting side note, if you observe a lot of ‘sort X’ followed by ‘sort Y’ you might consider adding a synonym between X and Y.) If a term or phrase is used often enough across different sessions we save this to an Elasticsearch index. Each time a document is indexed we look up the document in our index and add any popular search terms to a low ranking field. This guarantees a recall of the document but it will not automatically top the results for those queries. This is a two-step process. If your search engine supports partial updates of documents, go with that.
Before adding the last step we noticed that for some searches we boosted documents that didn’t get recalled and thus were never displayed to the user even though we knew it was a good hit!
Closing words
As a first step towards dynamic ranking this has shown good results. As long as your search engine supports query time boosting you can implement this.
By the way
It should be noted that SharePoint will actually do some of this for you. It comes with an interface meant to be used by an end user (as opposed to all search engines I’ve seen) and the UI contains the event listeners on all links, tracking what you do. This is fed into a database and the data does affect ranking. As far as I know only the last search term before a click is associated with the clicked link.
[1] One scenario that Piwik and click tracking does not pick up is if the sought information is found in the returned teasers. Search sessions that don’t end in a click might in fact have a happy ending.







A small discussion on the blog about scalability going on over at Reddit.com
Hi Christian,
great article!
Is your code available somewhere? I’m most interested in the part that gets the data from Piwik to Neo4j.
Thanks!
Georg
Christian doesn’t work at Comperio anymore but we have a private repo which I think contains the code in question.
Get in touch at webmaster () comperiosearch com and I’ll take a look at it.