Tech choices for the seasonal recipes app: A skeleton architecture for working with search relevancy
Although the concepts and sketches for the recipe app are the absolute best of the best, we were unfortunately forced to realize that an actual search solution must take the step down from the platonic world of pure ideas and into the hideous, gory and appalling world of bits, slime and bytes.
Luckily we got some help in our decision process. Elasticsearch presented itself to us as self-evident. qbox.io helped us out with hosting (Thank you guys!). We needed something at least equally cool to create the front end stuff, somewhere to flesh out the design and user interface. We chose AngularJS, perhaps out of ignorance and old habits, it hasn’t failed us yet.
Now we had the most important parts of the tech stack figured out, we had to figure out how to enable communication between the two. We imagined that somehow the user would “do something” in the web part, and his/her actions would be “sort of transferred” back into elasticsearch, which in turn would perform some tricks to find out the most relevant information, and return it back to AngularJS. We soon realized that we didn’t want to communicate directly with elasticsearch from the browser, although it is possible (using for instance elasticsearch-angular.js). Putting an elasticsearch instance directly available on the internet is very easy. Unfortunately, it leaves your node freely available to anyone. Elasticsearch is controlled by issuing calls to the REST API, such as
|
1 |
curl -XDELETE 'http://localhost:9200/indexname/' |
Which will, yes you guessed it, delete the index named indexname. While we truly believe in empowering the user, we also believe there has to be limits. There are several options for locking down the service. One very common option is to block port 9200 in the firewall, and set up a web server/proxy such as nginx that can route web traffic to a selected address like, say, /search to a specific address on the server running on port 9200 inside the box. That way you can protect elasticsearch, and open just the parts you want to allow traffic on.
In the end we actually did use nginx as a webserver and proxy, but we didn’t pass the queries straight to elasticsearch.
We made ourselves a tiny search client in the middle. Some of the reasons were:
- Separation of concerns
- Security
- Testability
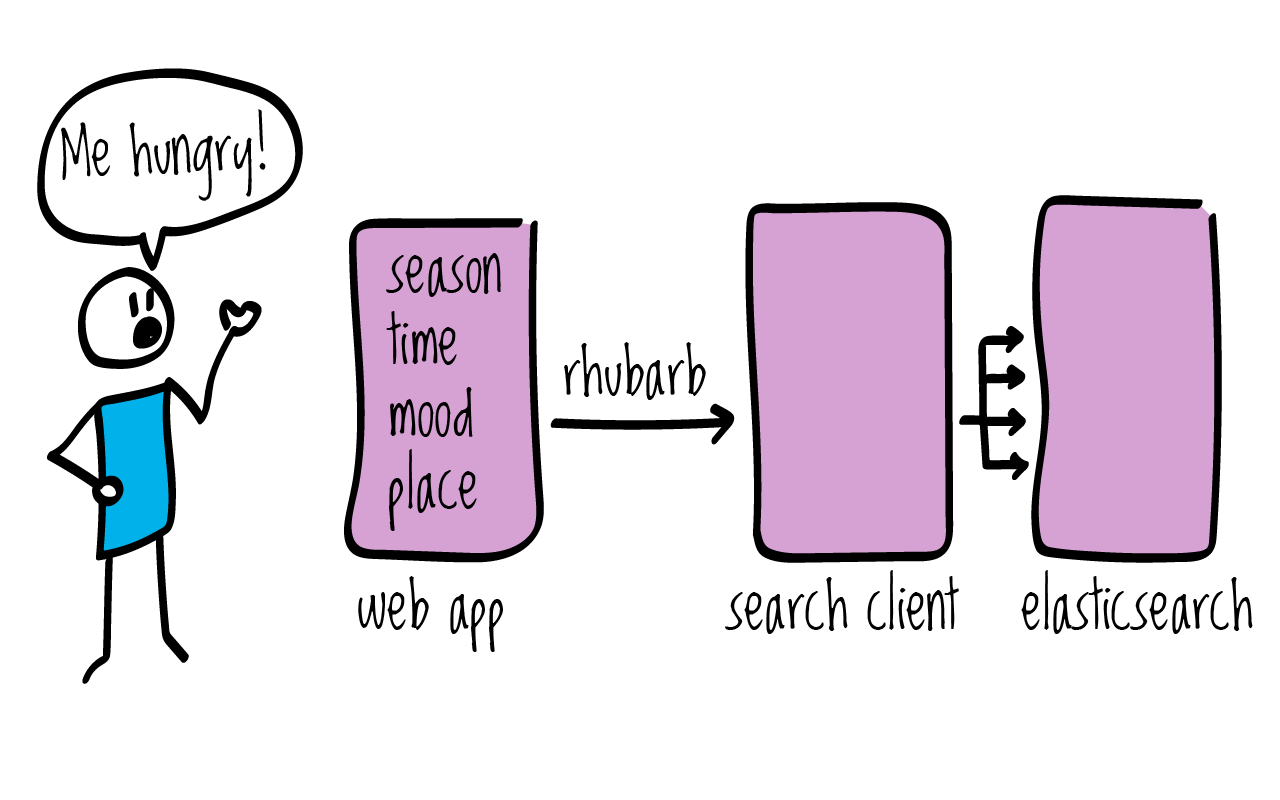
The search architecture
The recipe web-app takes care of getting some explicit input from the user. In addition to that, we may gather some implicit information to use as “hints”, for instance the time of day, the day of the week, the month of the year, geo-location, browser/mobile/os and so on. The web-app sends parameters to the search client as a simple GET query i.e. /search?ingredients=potet and receives in return the unmodified elasticsearch JSON response.
By separating the search logic from the user interface, we can easily test the results of modifying query parameters such as what fields to search in and what weight to give to different fields. Modifying details of the elasticsearch query can be done without fear of accidentally breaking something in the front end. We could even swap out the entire search engine without having the front end notice.
The search client is implemented in ruby, using grape, a tool to build lightweight REST- like APIS. Connecting and talking to elasticsearch is taken care of by the official elasticsearch ruby client.
The skeleton code for the search client is available on github. We have stripped away the “special” queries, leaving only the most generic functionality needed to start creating a search solution. It can receive query parameters, issue queries to elasticsearch and return the unmodified response, and log it. In actual implementations we have added complexity to the queries, functions that retrieve only facets, or query in different subsets of the index.
Feel free to fork the project and tailor it to your own needs. If you have suggestions for improvements, don’t be shy about it, create a pull request.
Sounds nice? This is work in progress, so check back every now and then for new blog posts.
Related Posts
 Elasticsearch: Indexing SQL databases. The easy way.
Elasticsearch: Indexing SQL databases. The easy way. Dictatorial control over recipe search results using elasticsearch and function_score
Dictatorial control over recipe search results using elasticsearch and function_score The Seasonal Food Recipe Web Application
The Seasonal Food Recipe Web Application User Experience for the Recipe App on Ipads and Android Tablets
User Experience for the Recipe App on Ipads and Android Tablets Search without search box: Recipe App – Alpha version
Search without search box: Recipe App – Alpha version The seasonal recipe app: Tapping into the mental model
The seasonal recipe app: Tapping into the mental model

