Solr: Indexing SQL databases made easier! – Part 2
Last summer I wrote a blog post about indexing a MySQL database into Apache Solr. I would like to now revisit the post to update it for use with Solr 5 and start diving into how to implement some basic search features such as
- Facets
- Spellcheck
- Phonetic search
- Query Completion
Setting up our environment
The requirements remain the same as with the original blogpost:
- Java 1.7 or greater
- A MySQL database
- A copy of the sample employees database
- The MySQL jdbc driver
We’ll now be using Solr 5, which runs a little differently from previous incarnations of Solr. Download Solr and extract it to a directory of your choice.Open a terminal and navigate to your Solr directory.
Start Solr with the command
bin/solr start .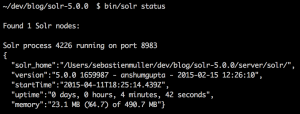
To confirm Solr successfully started up, run bin/solr status
Unlike previously, we now need to create a Solr core for our employee data. To do so run this command bin/solr create_core -c employees -d basic_configs . This will create a core named employees using Solr’s minimal configuration options. Try bin/solr create_core -help to see what else is possible.
- Open server/solr/employees/conf/solrconfig.xml in a text editor and add the following within the config tags:
1234567<lib dir="../../../dist/" regex="solr-dataimporthandler-\d.*\.jar" /><requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"><lst name="defaults"><str name="config">db-data-config.xml</str></lst></requestHandler>
- In the same directory, open schema.xml and add this this line:
1<dynamicField name="*_name" type="text_general" multiValued="false" indexed="true" stored="true" /> - Create a lib subdir in server/solr/employees and extract the MySQL jdbc driver jar into it.
- Finally, restart the Solr server with the command bin/solr restart
When started this way, Solr runs by default on port 8983. Use bin/solr start -p portnumber and replace portnumber with your preferred choice to start it on that one.
Navigate to http://localhost:8983/solr and you should see the Solr admin GUI splash page. From here, use the Core Selector dropdown button to select our employee core and then click on the Dataimport option. Expanding the Configuration section should show an XML response with a stacktrace with a message along the lines of Can't find resource 'db-data-config.xml' in classpath . This is normal as we haven’t actually created this file yet, which stores the configs for connecting to our target database.
We’ll come back to that file later but let’s make our demo database now. If you haven’t already downloaded the sample employees database and installed MySQL, now would be a good time!
Setting up our database
Please refer to the instructions in the same section in the original blog post. The steps are still the same.
Indexing our database
Again, please refer to the instructions in the same section in the original blog post. The only difference is the Postman collection should be imported from this url instead. The commands you can use alternatively have also changed and are now
|
1 2 3 4 5 6 7 8 |
Clear index: http://localhost:8983/solr/employees/update?stream.body=<delete><query>*:*</query></delete>&commit=true Retrieve all: http://localhost:8983/solr/employees/select?q=*:*&omitHeader=true Index db: http://localhost:8983/solr/employees/collection1/dataimport?command=full-import Reload core: http://localhost:8983/solr/employees/admin/cores?action=RELOAD&core=collection1 Georgi query: http://localhost:8983/solr/employees/select?q=georgi&wt=json&qf=first_name%20last_name&defType=edismax Facet query: http://localhost:8983/solr/employees/select?q=*:*&wt=json&facet=true&facet.field=dept_s&facet.field=title_s&facet.mincount=1&rows=0 Gorgi spellcheck: http://localhost:8983/solr/employees/select?q=gorgi&wt=json&qf=first_name&defType=edismax Georgi Phonetic: http://localhost:8983/solr/employees/select?q=georgi&wt=json&qf=first_name%20last_name%20phonetic&defType=edismax |
The next step
We should now be back where we ended with the original blog post. So far we have successfully
- Setup a database with content
- Indexed the database into our Solr index
- Setup basic scheduled delta reindexing
Let’s get started with the more interesting stuff!
Facets
Facets, also known as filters or navigators, allow a search user to refine and drill down through search results. Before we get started with them, we need to update our data import configuration. Replace the contents of our existing db-data-config.xml with:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
select e.emp_no as 'id', e.birth_date, ( select t.title order by t.`from_date` desc limit 1 ) as 'title_s', e.first_name, e.last_name, e.gender as 'gender_s', d.`dept_name` as 'dept_s' from employees e join dept_emp de on de.`emp_no` = e.`emp_no` join departments d on d.`dept_no` = de.`dept_no` join titles t on t.`emp_no` = e.`emp_no` group by e.`emp_no` limit 1000; |
To be able to facet, we need appropriate fields upon which to actually facet. Our new SQL retrieves additional fields such as employee titles and departments. Fields perfect for use as facets.
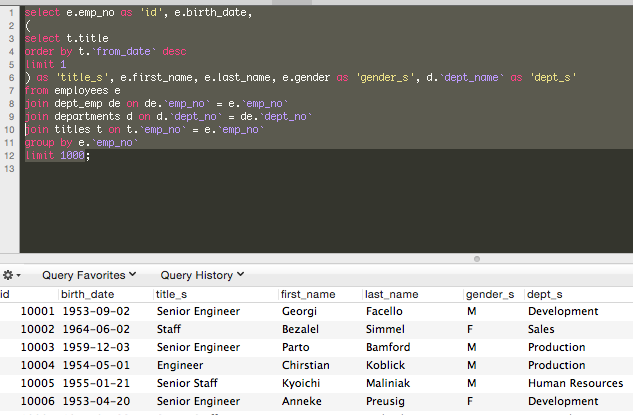
You’ll notice we map title, gender and dept_name to title_s, gender_s and dept_s respectively. This allows us to take advantage of an existing dynamic field mapping in Solr’s default basic config, *_s. A dynamic field allows us to assign all fields with a certain pre/suffix the same field type. In this case, given the field type
<dynamicField name="*_s" type="string" indexed="true" stored="true" /> , any fields ending with _s will be indexed and stored as basic strings. Solr will not tokenise them and modify their contents. This allows us to safely use them for faceting without worrying about department titles being split on white spaces for example.
- Clear the index and restart Solr.
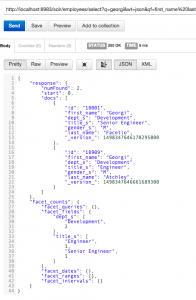
- Once Solr has restarted, reindex the database with
our new SQL. Don’t be alarmed if this takes a bit longer
than previously. It’s a bit more heavy weight and not
very well optimised! - Once it’s done indexing, we can
confirm it was successful by running the facet query via
Postman or directly in our browser. - We should see two hits for the query “georgi” along with
facets for their respective titles and department.
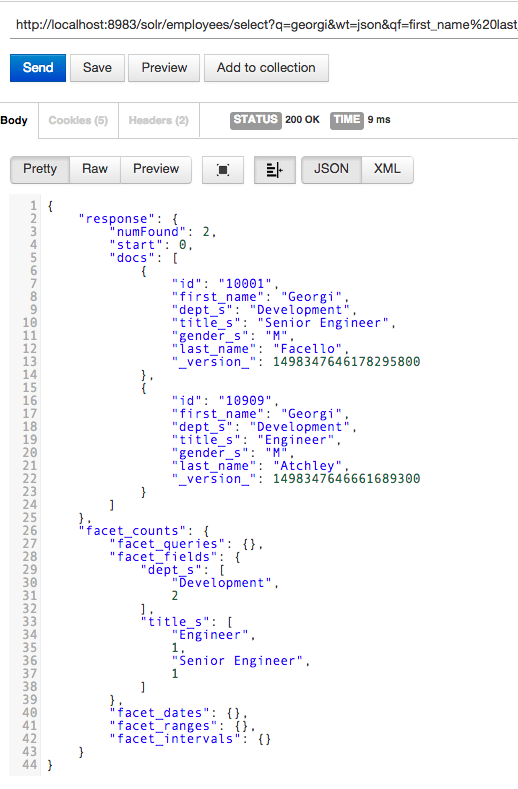
The anatomy of a facet query
Let’s take a closer look at the relevant request parameters of our facet query: http://localhost:8983/solr/employees/select?q=georgi&wt=json&qf=first_name%20last_name&defType=edismax&omitHeader=true&facet=true&facet.field=dept_s&facet.field=title_s&facet.mincount=1
- facet – Tells Solr to enable or prevent faceting. Accepted values include yes,on and true to enable, no, off and false to disable
- facet.field – Which field we want to facet on, can be defined multiple times
- facet.mincount – The minimum number of values for a particular facet value the query results includes for it to be included in the facet result object. Can be defined per facet field with this syntax f.fieldName.facet.mincount=1
There are many other facet parameters. I recommend taking a look at the Solr wiki pages on faceting and other possible parameters.
Spellcheck
Analysing query logs and focusing on those queries that gave zero hits is a quick and easy way to see what can and should be done to improve your search solution. More often than not you will come across a great deal of spelling errors. Adding spellcheck to a search solution gives such great value for a tiny bit of effort. This fruit is so low hanging it should hit you in the face!
To enable spellcheck, we need to make some configuration changes.
- In our schema.xml, add these two lines after the *_name dynamic field type we added earlier:
12<copyField source="*_name" dest="spellcheck" /><field name="spellcheck" type="text_general" indexed="true" stored="true" multiValued="true" />
A copyField checks for fields whose names match the pattern defined in source and copies their destinations to the dest field. In our case, we will copy content from first_name and last_name to spellcheck. We then define the spellcheck field as multiValued to handle its multiple sources.
- Add the following to our solrconfig.xml:
1234567891011121314151617181920212223242526<searchComponent name="spellcheck" class="solr.SpellCheckComponent"><str name="queryAnalyzerFieldType">text_general</str><!-- a spellchecker built from a field of the main index --><lst name="spellchecker"><str name="name">default</str><str name="field">spellcheck</str><str name="classname">solr.DirectSolrSpellChecker</str><!-- the spellcheck distance measure used, the default is the internal levenshtein --><str name="distanceMeasure">internal</str><!-- minimum accuracy needed to be considered a valid spellcheck suggestion --><float name="accuracy">0.5</float><!-- the maximum #edits we consider when enumerating terms: can be 1 or 2 --><int name="maxEdits">2</int><!-- the minimum shared prefix when enumerating terms --><int name="minPrefix">1</int><!-- maximum number of inspections per result. --><int name="maxInspections">5</int><!-- minimum length of a query term to be considered for correction --><int name="minQueryLength">4</int><!-- maximum threshold of documents a query term can appear to be considered for correction --><float name="maxQueryFrequency">0.01</float><!-- uncomment this to require suggestions to occur in 1% of the documents<float name="thresholdTokenFrequency">.01</float>--></lst></searchComponent>
This will create a spellchecker component that uses the spellcheck field as its dictionary source. The spellcheck field contains content copied from both first and last name fields.
- In the same file, look for the select requestHandler and update it to include the spellcheck component:
123456789101112131415<requestHandler name="/select" class="solr.SearchHandler"><!-- default values for query parameters can be specified, thesewill be overridden by parameters in the request--><lst name="defaults"><str name="echoParams">explicit</str><int name="rows">10</int><str name="spellcheck">on</str><str name="spellcheck.dictionary">default</str></lst><!-- Add this to enable spellcheck --><arr name="last-components"><str>spellcheck</str></arr></requestHandler>
The defaults list in a requestHandler defines which default parameters to add to each request made using the chosen request handler. You could, for example, define which fields to query. In this case we’re enabling spellcheck and using the default dictionary as defined in our solrconfig.xml. All values in the defaults list can be overwritten per request. To include request parameters that cannot be overwritten, we would need to use an invariants list instead:
|
1 2 3 |
<lst name="invariants"> <str name="defType">edismax</str> </lst> |
Both lists can be used simultaneously. When duplicate keys are present the values in the invariants list will take precedence.
Once we’ve made all our configuration changes, let’s restart Solr and reindex. To verify the changes worked, do a basic retrieve all query and check the resulting documents for the spellcheck field. Its contents should be the same as the document’s first_name and last_name fields.
Because we have enabled spellcheck by default, queries with possible suggestions will include contents in the spellcheck response object.
queries with possible suggestions will include contents in the spellcheck response object.
Try the Gorgi spellcheck query and experiment with different queries. To query the last_name field as well, change the qf parameter to qf=first_name last_name.
The qf parameter defines which fields to use as the search domain.
When the spellcheck response object has content, you can easily use it to implement a basic “did you mean” feature. This will vastly improve your zero hit page.
Phonetic Search
Now that we have a basic spellcheck component in place, the next best feature that easily creates value in a people search system is phonetics. Solr ships with some basic phonetic tokenisers. The most commonly used out of the box phonetic tokeniser is the DoubleMetaphoneFilterFactory. It will suffice for most use cases. It does, however, have some weaknesses, which we will go into briefly in the next section.
We need to once again modify our schema.xml to take advantage of Solr’s phonetic capabilities. Add the following:
|
1 2 3 4 5 6 7 8 9 |
<fieldType name="phonetic" class="solr.TextField" > <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.DoubleMetaphoneFilterFactory" inject="true" maxCodeLength="4"/> </analyzer> </fieldType> <copyField source="*_name" dest="phonetic" /> <field name="phonetic" type="phonetic" indexed="true" stored="false" multiValued="true" /> |
Similar to spellcheck, we copy contents from the name fields into a phonetic field. Here we define a phonetic field, whose values will not be stored as we don’t need to return them in search results. It is, however, indexed so we can actually include it in the search domain. Finally, like spellcheck, it is multivalued to handle multiple potential sources. The reason we create an additional search field is so we can apply different weightings to exact matches and phonetic matches.
Restart Solr, clear the index and reindex.
Running the Georgi Phonetic search request should now returns hits based on exact and phonetic matches. To ensure that exact matches are ranked higher, we can add a query time boost to our query fields: &qf=first_name last_name phonetic^0.5
Rather than apply boosts to fields we want to rank higher, it’s usually simpler to apply a punitive boost to fields we wish to rank lower. Replace the qf parameter in the Georgi Phonetic request and see how the first few results all have an exact match for georgi in the first_name field.
Query Analysis
As we look further down the result set, you will notice some strange matches. One employee, called Kirk Kalsbeek, is apparently a match for “georgi”. To understand why this is a match, we can use Solr’s analysis tool.
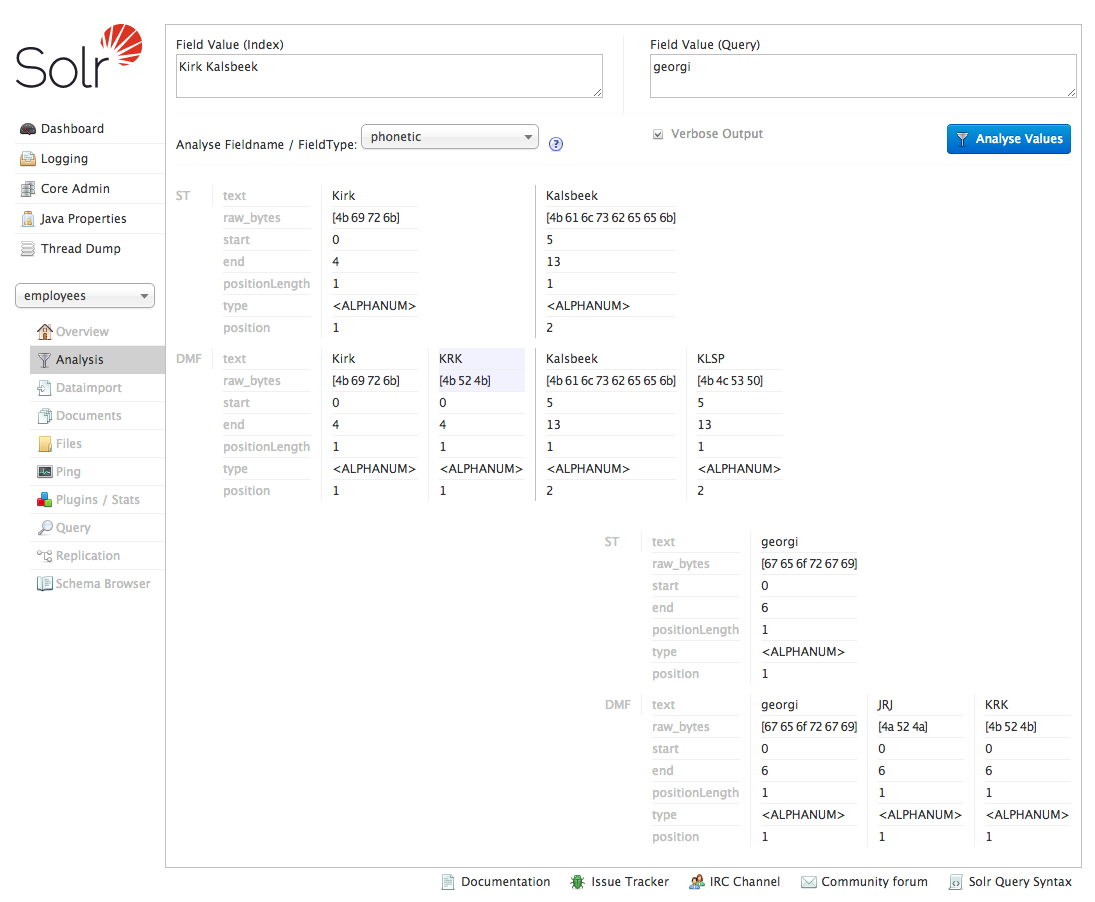
It allows use to define an indexed value, a query value and the field type to use and then demonstrate how each value is tokenised and whether or not the query would result in a match.
With the values Kirk Kalsbeek, georgi and phonetic respectively, the analysis tool shows us that Kirk gets tokenised to KRK by our phonetic field type. Georgi is also tokenised to KRK, which results in a match.
To create a better phonetic search solution, we would have to implement a custom phonetic tokeniser. I came across an example, which has helped me enormously in improving phonetic search for Norwegian names on a project.
Conclusion
We should now be able to
- Implement index field based spellcheck
- Use basic faceting
- Implement Solr’s out of the box phonetic capabilities
Query completion I will leave for the next time. I promise you won’t have to wait as long between posts as last time :)
Let me know how you get on in the comments below!


Hi Seb,
Great article.
what steps do i take if i want to search through multiple tables?
Do I add more entity tags in db-data-config.xml?
I’d love to hear you thought about this.
-Dahir
Hi Dahir, glad you found it useful! That’s right, adding more entity tags will allow you to carry out multiple indexing queries at the same time. You can even define multiple data source connections if you need to retrieve data from different databases. Take a look at this gist https://gist.github.com/sebnmuller/03935f1384e150504363#file-multiple-entitites for an example of defining multiple entities. Key thing to note is the use of the name tags, both for the connection and entity. If using the same database connection the dataSource tag is unnecessary.
thanks the article is useful,
i have an issue with full-import of data:
i only get 10 rows fetched from the database i tried adding batchSize=”-1″ to the db-data-config file but also didnot work.
Hi Abdullah! What does your db-data-config file look like? Do you have any constraints, in a where clause for example, that might result in only 10 rows being returned?
Great article. I have been toying with Solr the last couple of days. In following your article, I have faced these two issues, thus far:
1. While following the facets, section, I tried the new SQL query statement and it did not fetch anything. I then directly copied it in phpmyadmin mySQL interface and I get this error: “#1052: Column ‘emp_no’ in group statement is ambiguous”
2. Clear index command: http://localhost:8983/solr/employees/update?stream.body=*:*&commit=true
gives back error message
Please help, as I want to start the Facet part of the tutorial.
Hi George, glad you’ve enjoyed the article, and sorry for the issues! Change the group by line in the SQL query statement to
group by e.emp_no. The clear index command should also be http://localhost:8983/solr/employees/update?stream.body=<delete><query>*:*</query></delete>&commit=true instead. I’ll update the article to reflect this changes. Let me know if you encounter any further issues.