Replacing FAST ESP with Elasticsearch at Posten
First, some background
A few years ago Comperio launched a nifty service for Posten Norge, Norway’s postal service. Through the service, retail companies can upload their catalogues and seasonal flyers to make the products listed within searchable. Although the catalogue handling and processing is also very interesting, we’re going to focus on the search side of things in this post. As Comperio has a long relationship and a great deal of experience with FAST ESP, this first iteration of Posten’s Tilbudssok used it as the search backend. It also incorporated Comperio Front, our search middleware product, which recently had a big release. .
Newer is better
Unfortunately, FAST ESP is getting on a bit and as a result Tilbudssok has been limited by what we can coax out of it. To ensure we provide the best possible search solution we decided it was time to upgrade and chose Elasticsearch as the best candidate. If you are unfamiliar with Elasticsearch, take a moment to browse our other blog posts on the subject. The resulting project had three main requirements:
- Replace Fast ESP with Elasticsearch while otherwise maintaining as much of the existing architecture as possible
- Add geodata to products such that a user could find the nearest store where they were available
- Setup sexy log analysis with Logstash and Kibana
Data Sources, Ingestion and Processing
The data source for the search system is a MySQL database populated with catalogue and product data. A separate Comperio system generates this data when Posten’s customers upload PDFs of their brochures i.e. we also fully own the entire data generation process.
The FAST ESP based solution made use of FAST’s JDBC connector to feed data directly to the search index. Inspired by Christoffers blog post, we made use of the JDBC plugin for Elasticsearch. This allowed us to use the same SQL statements to feed Elasticsearch. It took us no more than a couple of hours, including some time wrestling with field mappings, to populate our Elasticsearch index with the same data as the FAST one.
We then needed to add store geodata to the index. As mentioned earlier, we completely own the data flow. We simply extended our existing catalogue/product uploader system to include a store uploader service. Google’s geocoder handled converted addresses to coordinates for use with Elasticsearch’s geo distance sorting. We now had store data in our database. An extra JDBC river and another round of mapping wrestling got that same data into the Elasticsearch index.
Our approach
Before the conversion to Elasticsearch, the Posten system architecture was typical of most Comperio projects. Users interact with a Java based frontend web application. This in turn sends queries to Comperio’s search abstraction layer, Comperio Front. This formats requests such that the system’s search engine, in our case FAST ESP, can understand them. Upon receiving a response from the search engine, Front then formats it into a frontend friendly format i.e. JSON or XML depending on developer preference.
Unfortunately, when we started the project, Front’s Elasticsearch adapter was still a bit immature. It also felt a bit over kill to include it when Elasticsearch has such a robust Java API already. I saw an opportunity to reduce the system’s complexity and learn more about interacting with Elasticsearch’s Java API and took it. With what I learnt, we could later beef up Front’s Elasticsearch adapter for future projects.
As a side note, we briefly flirted with the idea of replacing the entire frontend with a hipstery Javascript/Node.js ecosystem. It was trivial to throw together a working system very quickly but in the interest of maintaining existing architecture and trying to keep project run time down we opted to stick with the existing Java based MVC framework.
After a few rounds of Googling, struggling with documentation and finally simply diving into the code, I was able to piece together the bits of the Elasticsearch Java API puzzle. It is a joy to work with! There are builder classes for pretty much everything. All of our queries start with a basic SearchRequestBuilder. Depending on the scenario, we can then modify this SRB with various flavours of QueryBuilders, FilterBuilders, SortBuilders and AggregationBuilders to handle every potential use case. Here is a greatly simplified example of a filtered search with aggregates:
Logstash and Kibana
With our Elasticsearch based system up ready to roll, the next step was to fulfil our sexy query logging project requirement. This raised an interesting question. Where are the query logs? As it turns out, (please contact us if we’re wrong), the only query logging available is something called slow logging. It is a shard level log where you can set thresholds for the query or fetch phase of the execution. We found this log severely lacking in basic details such as hit count and actual query parameters. It seemed like we could only track query time and the query string.
Rather than fight with this slow log, we implemented our own custom logger in our web app to log salient parts of the search request and response. To make our lives easier everything is logged as JSON. This makes hooking up with Logstash trivial, as our logstash config reveals:
Kibana 4, the latest version of Elastic’s log visualisation suite, was released in February, around the same time as we were wrapping up our logging logic. We had been planning on using Kibana 3, but this was a perfect opportunity to learn how to use version 4 and create some awesome dashboards for our customer:
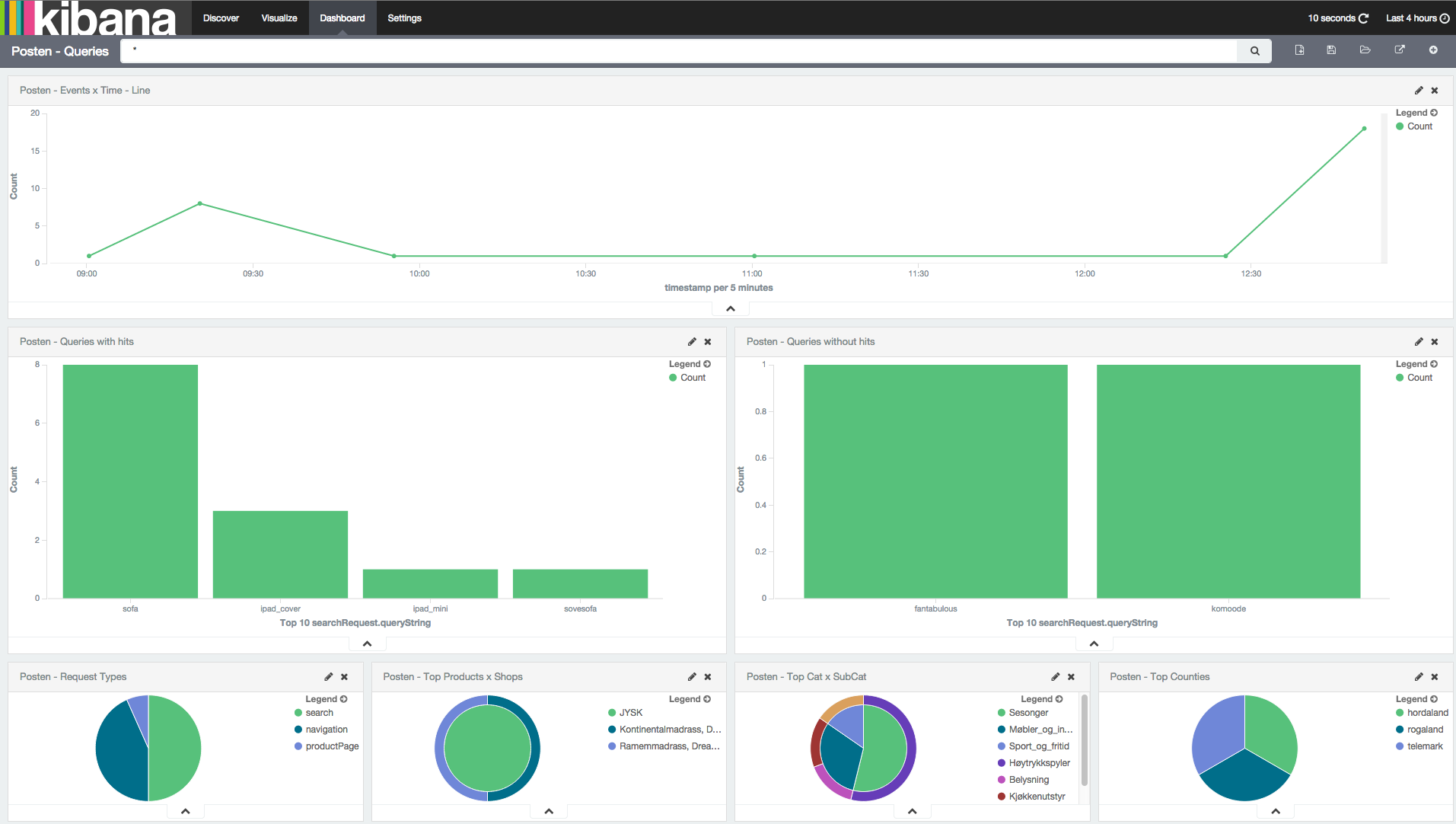
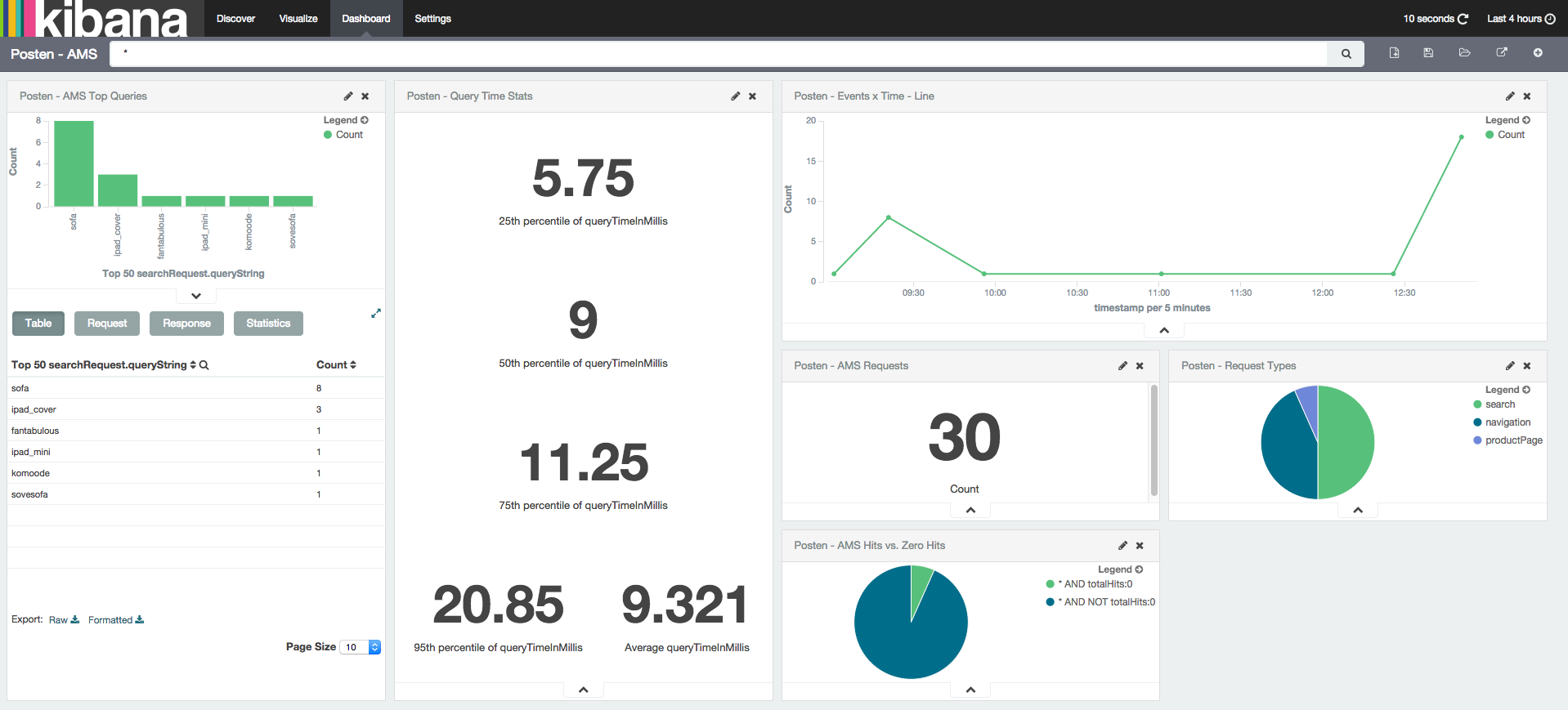
Kibana 4 is wonderful to work with and will generate so much extra value for Posten and their customers.
Conclusion
- Although the Elasticsearch Java API itself is well rounded and complete, its documentation can be a bit frustrating. But this is why we write blog posts to share our experiences!
- Once we got past the initial learning curve, we were able to create an awesome Elasticsearch Java API toolbox
- We were severely disappointed with the built in query logging. I hope to extract our custom logger and make it more generic so everyone else can use it too.
- The Google Maps API is fun and super easy to work with
Rivers as a data ingestion tool have long been marked for deprecation. When we next want to upgrade our Elasticsearch version we will need to replace them entirely with some other tool. Although Logstash is touted as Elasticsearch’s main equivalent of a connector framework, it currently lacks classic Enterprise search data source connectors. Apache Manifold is a mature open source connector framework that would cover our needs. The latest release has not been tested with the latest version of Elasticsearch, but it supports versions 1.1-3.
Once the solution goes live, during April, Kibana will really come into its own as we get more and more data.





Thanks for the article, Seb! It was interesting to read.
I have a question about data ingestion. Do you parse those PDFs uploaded by the customers? If yes – how do you manage them all? Do you have some sort of a dashboard for all those imports (e.g. with data format validity status, import stats for each customer, etc.) and a person who manage them all and communicate with customers?
At our project we deal with XML data imports and managing them is a real problem that needs a separate admin dashboard and a person that manages all those imports and communicates with our data providers (e.g. advertising sites, realty agencies etc.).
Hi Sergii, glad you liked it!
We parse the PDFs uploaded by the customers, individual products are extracted and tagged and then managed with a dashboard as you describe.
We’re looking into options for automating more of this process at the moment but it’s pretty streamlined as is.
What main problems do you face?