Bitbucket to Elasticsearch Connector
![]()
“Ability to search source code? (BB-39)” is an issue created in July 2011 on Bitbucket and its status is still new. If you have used Bitbucket before, you would have certainly noticed that there is no way to search in a repository’s source code. Now what if you had more than 200 repositories (as is the case for Comperio) and you wanted to search for some examples on how to use a function, for example? There are two options. Either clone all the repos to your local machine and then do some ‘grep’ magic or use our connector to index Bitbucket content in elasticsearch and then search happily ever after.
In this blog post, we introduce an open-source and free connector that indexes content from Bitbucket in elasticsearch. The connector is written in Python and it has two main modes: index, indexes everything from your Bitbucket account in elasticsearch, and update, updates your elasticsearch index based on the commits from the last time your ran the connector (there are three types of git update: add, change and delete).
The connector creates an elasticsearch index (based on the configurations provided in elasticsearch.conf) which in turn has two types of documents, namely ‘file’ and ‘repo’. We only provide a mapping file for the ‘file-typed’ documents, you can create one for repos as well. For information on the connector and how to use it, please see the project’s page on GitHub.
Bitbucket REST APIs
If you check the source code of the connector, you will see that we are using two versions of Bitbucket REST APIs (version 1.0 and version 2.0). We are doing so because not everything supported by version 1.0 is supported by version 2.0 and vice versa, e.g. branches are retrievable in API V 1.0 but not 2.0.
Field collapsing for duplicates from different branches
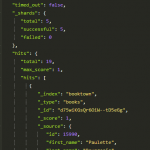
If a repo has more than one branch, the connector would index the files in all branches as separate documents. This means that whenever you are searching for something, you will see the same matching file from the different branches as separate hits as well. In order to avoid this, we created an ID called collapse_id which allows us to collapse hits of the same file, but from different branches, using queries similar to the following:
See another example of field collapsing using the top hits aggregation on elasticsearch.org.