Searching for “miljø” inside of “arbeidsmiljø” using Elasticsearch and the ngram tokenizer
Compound words are a big problem for Norwegians. The young don’t know how to use them, search engines struggle with them as well. Elasticsearch and the ngram tokenizer offers one possible solution.
There is a Facebook group dedicated to the task of spreading the knowledge, using images showing the difference between for instance “underbukser” (under wear) and “under bukser” (positioned below trousers).

Underwear or under wear. Not the same thing!
Photo: André Ulveseter
Elasticsearch offers a wide range of analysing options. The ngram tokenizer splits a string into a series of continuous letters. For instance “underbukser”, with a size two ngram would split the word into “un” “nd” “de” “er “rb” “bu “uk” “ks” “se” “er”. Elasticsearch will use the same analyzer when querying the field, so if we search for “bukser” it will be split into “bu”, “uk”, and so on, and matches will result.
Well, enough chit chat, time for some code. Using the excellent Play tool created by Elasticsearch experts found.no we can even test it all out in our browser, no need for a server, you can do it at home on your ipad, chromebook, or even on a windows phone.
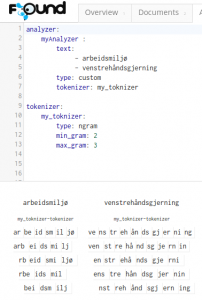
myAnalyzer in Action, showing how the word is split into ngrams
Here is a simple demo showing the ngram tokenizer in action.
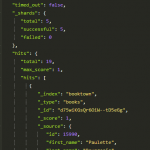
The demo has three documents indexed, all containing the field foo with respective values “arbeidsmiljø”, “arbeid”, and “arbeidsmiljøloven”.
It uses an analyzer aptly called “myAnalyzer”, this analyzer is using a custom tokenizer called “my_toknizer”, where the actual ngram tokenization is taking place. The ngrams for this sample are created with sizes ranging from 2 to 3. Testing it out on found.no/play, you can see how the various stages of the analyzer modifies the text. Neat!
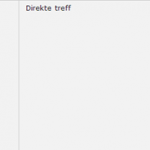
The mapping enables the “myAnalyzer” to be used for the “foo” field. Finally, I create a query, for the term “miljø”, which I expect to be found in the middle of documents nr. 2 and 3. Pressing the “run” button executes the setup, displaying the search results at the bottom right.
If you are really interested to learn more about analyzers, try the elasticsearch guide on languages, which is getting better day by day, or the articles on qbox on autocomplete using ngrams or found.no on language analyzers