FAST Search for Internet Sites
FAST Search Server 2010 for Internet Sites (FSIS) was released previously this fall, and the first implementations are already well under way. Here at Comperio, we are in the final phases of rolling out our first FSIS-based solution for a customer in Sweden.
For the first time since Microsoft’s acquisition of FAST, the broad audience can now reap the benefits of a high-end platform for enterprise search. This post is a first look at FSIS; a brief overview of the new components and what has kept Microsoft busy throughout the time since the acquisition. The post is simply intended to serve as an introduction to the curious, and makes no attempt to be comprehensive.
Previous incarnations of FAST technology have been equipped with powerful and flexible support for processing documents and indexing them accordingly. Out of a UX perspective, FAST technology has not been equally strong. With FSIS, Microsoft has recognized this imbalance by targeting what we at Comperio refer to as “search logic”. This area, which is both broad and complex, has given birth to several products and frameworks – one of them being Comperio Front. The future will have to decide if this first version of FSIS is strong enough to manage on its own.
The FSIS architecture
Both FSIS, and its sister-product FAST Search Server 2010 for Internal Applications (FSIA), are built around the proven technology in FAST ESP. More specifically, the very core of both these products is FAST ESP 5.3 with service pack 3 or higher.
In FSIS, ESP is fairly well hidden inside of the Microsoft packaging. New modules which encapsulate the existing ESP interfaces provide a high level of abstraction. Most prominent of the new modules are inarguably Content Transformation Services (CTS) and Interaction Management Services (IMS). These handle management and processing of indexing and query flows. There is also FAST Search Designer, a Visual Studio 2008 add-on, which makes it easy to create, debug, and orchestrate these flows. A fourth module, Search Business Manager targets business-users who need to adjust the overall search experience, and perhaps want to try out new features using the integrated A/B testing functionality.
There are also additional supporting modules, e.g. the IMS UI toolkit which provides a foundation for new web application projects. Another example is the Content Distributor Emulator, which provides backwards-compatibility for legacy ESP connectors. But on a high level, with only the most important modules listed, the structure of FSIS corresponds to the figure below.
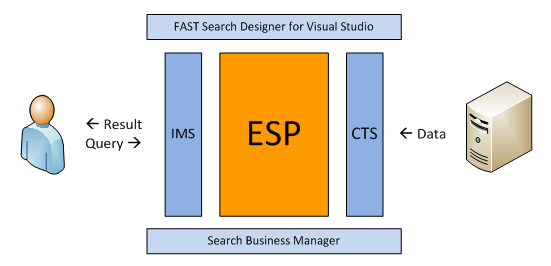
Anyone adventurous enough to seek complete and fine-grained control of their search solution will have to go deeper than the outer FSIS layers. ESP is still the go-to place for all advanced customizations, and is still available in its completeness.
Content and interaction workflows
The right part of the figure is typically described as the “content side” or the “source side” of the search solution. This is where CTS is located. Data to be indexed is sent to CTS, where it is manipulated and prepared for indexing according to business-rules and requirements. For example, it might be necessary to enrich certain documents with synonyms or additional keywords. All such logic is graphically mapped up in workflows, using either preconfigured or custom data manipulation “tasks”.
Those of us with experience of development from ESP will feel right at home in the workflow task library in CTS. Many features and functions are direct derivatives of those found in the traditional ESP Document Processing framework, but CTS provides a much-needed face-lift. Most developers will surely appreciate the improved development and debugging possibilities. It should be noted that the traditional Document Processing pipelines are still available; they are in fact still running behind the scenes.
IMS is located on the left side of the figure. Queries are both going in, and coming back out through the workflows in IMS. Just like documents flow through CTS, queries and result sets flow through IMS. The big difference is of course that instead of manipulating content, IMS brings support for tailoring the search experience: e.g. branching up a query into several federated searches, or conditionally enriching or expanding queries. As mentioned at the top of this post, FAST has traditionally been lagging behind in this area. In that regard, IMS is extremely welcome news for developers and business-users alike.
In future blog entries we will dig deeper and explore more of the capabilities in the new FAST-based offerings from Microsoft. We will surely revisit the concept of “search logic”, and how FSIS attempt to solve such problems. Until then, feel free to shoot us any comments or questions!





[...] This post was mentioned on Twitter by Mikael Svenson, Comperio. Comperio said: FAST Search for Internet Sites http://tinyurl.com/2wgjz4z [...]
Nice intro, Marcus. I’m waiting for the follow-up :) It would be nice with a getting-started guide with workflows and IMS.
Thanks Hans Terje! :)
Hi Marcus!
Is it correct that FAST Search Designer can be used to debug both content and query workflows? I dying for better debugging tools.
Looking forward to hear more about search logic, both in FSIS IMS and Comperio Front!
Marcus,
This was a very helpful overview of the newly released FAST Search for Internet Sites. I meet a lot of customers, both existing and potential future FAST users, who are a bit confused over the various new “tappings” of FAST from Microsoft; what do they contain, what are their strenghts and weaknesses, licensing models etc. This contribution is certainly a source for reflection I will lead them to in the future!
Vegard,
Yes, you can debug both CTS and IMS flows. No more print statements or Spy tasks!
Jørn,
I am not surprised! One thing you should make sure to explain for anyone with a FAST history: since ESP is readily available and fully functional, all applications compatible with ESP 5.3 (5.x really) is also compatible with FSIS. Of course, they can’t use the new functionality in CTS and IMS, but they can still upgrade, and make the transition to the new FSIS components progressively, at their own pace.
[...] Sharepoint users? MS has an offering to them as well, called FAST Search for Internet Sites. Read Comperio’s excellent blog article about it. A bit disappointing that the core is still the more than three year old ESP5.3 wrapped in [...]
[...] Next you can get a version of Fast Search tailored to index only Internet sites. Think of this as Microsoft’s answer to Google’s Site Search service. This version of Fast Search is called Fast Search for Internet Sites. The acronym in February 2011 was FSIS. Comperio posted some useful information about FSIS in its article “Fast Search for Internet Sites.” [...]
[...] http://blog.comperiosearch.com/blog/2010/11/10/fast-search-internet-sites/ [...]