Solr As A Document Processing Pipeline
Recently on a project I got an interesting request. Content owners wanted to enrich new documents submitted to the search index with content from documents already present in the index. We use Solr as the search backend for this particular customer so I started thinking about how to achieve this with Solr.
A bit of Solr background
Solr ships with all the tools and features necessary for an advanced search solution. These include the oft overlooked update request processors. They operate at the document level i.e. prior to individual field tokenisation and allow you to clean, modify and/or enrich incoming documents. Processing options include language identification, duplicate detection and HTML markup handling. Create a chain of them and you have a true document processing pipeline.
The Solr wiki includes a brief entry on the topic with an example of a custom processor that conditionally adds the field “cat” with value “popular”. The full list of UpdateRequestProcessor factories is available via the Solr Start project.
Back to the initial request
Certain incoming documents would contain a field, topicRef for example, with a reference to one or more documents already present in the index. The referenced documents could either contain a subsequent reference or content that we wanted to add to the incoming document. 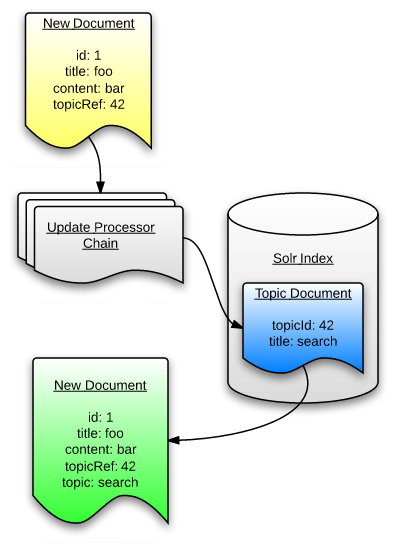
I needed a mechanism to retrieve any referenced documents, traverse a tree of subsequently referenced documents if necessary, and then map the eventual leaf documents’ specified content fields to additional new fields in the incoming document.
I created a recursive document enrichment processor to do just that!
Its settings allow for multiple potential field retrievals and mappings, local and foreign key field definitions and the option to retrieve content from a remote Solr index.
A minor drawback of the current iteration of the processor is a high reliance on the existence of referenced documents i.e. if the referenced documents are not already present in the index then the processor will skip over them. To ensure documents are fully enriched, especially if the referenced documents are included in the same indexing batch, reindexes of incoming documents is necessary unless explicitly defining the document indexing order.
In addition, when a referenced document is updated, content owners expect this to have an impact on the content of the parent document and therefore a user’s search experience. This is currently not the case as parent documents are unaware of their child documents beyond the indexing process.
I’m now thoroughly enjoying tackling these issues and working on the next iteration of this RecursiveMergeExistingDoc processor!
Update – 06/02/15
The source code is now available on github
Related Posts
 Idea: Your life searchable through Norch – NOde seaRCH, IFTTT and Google Drive
Idea: Your life searchable through Norch – NOde seaRCH, IFTTT and Google Drive Dynamic search ranking using Elasticsearch, Neo4j and Piwik
Dynamic search ranking using Elasticsearch, Neo4j and Piwik How To: Debug and log FAST Search pipeline extensibility stages in Visual Studio
How To: Debug and log FAST Search pipeline extensibility stages in Visual Studio Solr: Indexing SQL databases made easier!
Solr: Indexing SQL databases made easier! Solr: Indexing SQL databases made easier! – Part 2
Solr: Indexing SQL databases made easier! – Part 2 Analysing Solr logs with Logstash
Analysing Solr logs with Logstash


Did your custom UpdateRequestProcessor works on distributed mode or only on “local” mode? Any chance you can share your code this could be highly educative for people out there wanting to customize their Solr setup.
It works distributed in the sense that it can retrieve existing documents from other non-local Solr instances.
I’ll try get some code examples up asap, I’m working on refining it a bit and extending it this week.
Apart from the demo code at https://wiki.apache.org/solr/UpdateRequestProcessor there’s not a lot around online unfortunately!
——–
The source code is now up on github:
https://github.com/sebnmuller/SolrDocumentEnricher