Using Parent/Child Relationships for Document Security in Elasticsearch
Problem description
Our documents have a huge content part with text, images, title, author, etc. that rarely or never changes.
Other metadata fields can change more often and are only used for filtering, not relevancy scoring. The example meta data I will use here is a ‘classification’.
When the classification or other status changes, we would prefer not to have to refeed and reindex the entire document. This would cause Elasticsearch to invalidate the old version by marking it as deleted and create a new version, causing a lot of disk space to be used, as well as having to refeed a lot of unchanged data again.
Solution
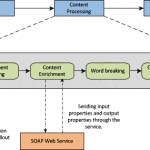
One way to solve this is by utilising the new parent/child relationship feature that came with Elasticsearch 1.0. We can split a document in two parts, one containing the big static payload, and one containing the metadata we want to use for document security filtering. One will be the parent and one will be the child, and since we only have one of each in this scenario, it doesn’t matter which is which, I will chose the metadata as the parent and the main content part as the child in this example.
Say we have two confidentiality classification levels: ‘public’ and ‘secret’, and our documents contain a title and a body. Let’s call the different parts of our document meta and content. What could have been one document with three fields
|
1 |
one_doc: classification, title, body |
will now be split into
|
1 2 |
meta: classification content: title, body |
First we need to create an index and a mapping where we set up the parent/child relationship between our two document parts as two individual types. (Here using Marvel/Sense syntax for readability. You can always use cURL if you don’t have Sense.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
POST /dsdemo { "settings": { "number_of_shards": 1, "number_of_replicas": 0 }, "mappings": { "meta": { "properties": { "classification": { "type": "string" } } }, "content": { "_parent": { "type": "meta" }, "properties": { "title": { "type": "string" }, "body" : { "type": "string" } } } } } |
Now let’s create some of the main content documents. We will use the same ID for the content document part and the meta document part. (This is not a requirement, it simply makes it easier to keep track of the related parts this way.) The parent ID that we refer to here is the ID of the parent document, of the parent document type. These documents do not yet exist, and they don’t have to. So I create the content documents here first just to emphasise that point.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
POST /dsdemo/content/1?parent=1 { "title": "The first document", "body": "This could be huge #1" } POST /dsdemo/content/2?parent=2 { "title": "The second document", "body": "This could be huge #2" } POST /dsdemo/content/3?parent=3 { "title": "The third document", "body": "This could be huge #3" } POST /dsdemo/content/4?parent=4 { "title": "The fourth document", "body": "This could be huge #4" } |
Now let’s create the parent documents that holds the classification field. Start by setting them all to public:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
POST /dsdemo/meta/1 { "classification": "public" } POST /dsdemo/meta/2 { "classification": "public" } POST /dsdemo/meta/3 { "classification": "public" } POST /dsdemo/meta/4 { "classification": "public" } |
Then see what happens when we search for all ‘public’ documents containing the word ‘huge’:
|
1 2 3 4 5 6 7 8 9 10 11 |
GET /dsdemo/content/_search?q=huge { "filter": { "has_parent": { "parent_type": "meta", "query": { "term": {"classification": "public"} } } } } |
This reveals all four documents.
Now let’s change the classification for the first document:
|
1 2 3 4 |
POST /dsdemo/meta/1 { "classification": "secret" } |
Search again, and there should now be only three public documents.
Closing notes
- Use numeric/enumerated classification levels instead, so we can more easily return all below a certain level.
- Another document security dimension could be an access control list consisting of user names or user groups.
- It seems unnecessary that we have to specify “parent_type”: “meta” in the query, as this is already set up in the mapping. But imagine if you did not search for only content type documents, but rather any document type; then it would be needed.