Making your Fast Search for SharePoint-life easier with ElasticSearch.
Last week we were trying to track down a document that, based on customer feedback, must have been lost somewhere between the content source and the index. By turning on the Fast Pipeline stage FFDdumper and doing a full crawl we determined that the document at least had made it to the FAST pipeline. Our third party connector did its job and the blame was either on SharePoint or Fast. The next step was to inspect SharePoint’s crawl logs. They look like this:

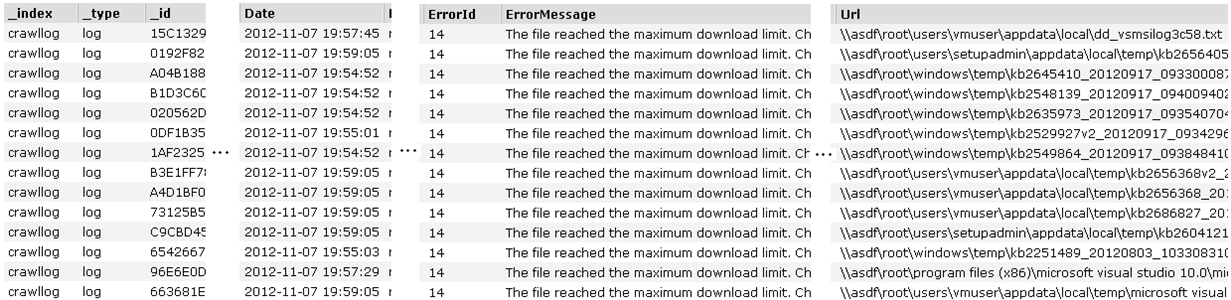
In this example I have simply crawled the c: drive on my virtual machine with SharePoint to generate some entries in the crawl log. 269 errors aren’t that many; you could click the link and inspect the log manually in a reasonable amount of time. Viewing the logs will let you inspect 50 documents at a time.

This gets boring really fast. Therefore we started to use the API for extracting crawl logs from SharePoint [3] programmatically. Because of the API’s deprecated status the documentation is a bit on the thin side. Luckily there are some examples in the blogosphere [1,2] that helped us along and we could soon dump the crawl logs to file and ctrl-f for our missing document. Of course, the script could find the log entry and only show you the relevant one. However with a large crawl log it can take hours to extract all the log entries. It is better to dump them all to file should you need to look for a second or third file later.
Using grep, findstr or ctrl-f for searching feels wrong when you work as a search consultant. Instead the natural instinct when something large should be searched through is to index it. One option was to index it back into SharePoint through BDC (and get a possible nasty loop with reading and creating logs) or to use the old Fast API directly, bypassing SharePoint. Both felt a little heavy duty for this one-off job, and that’s when we put ElasticSearch to play. ElasticSearch is a fairly new search engine built on Lucene, and sometimes referred to as “The new kid on the block” in the Open Source Community where there’s some friendly rivalry between the Solr and ElasticSearch camps. It is a 20MB download and is ready to index documents mere seconds after you unzip the package. To index a document you simply POST some JSON to a REST endpoint and that is it. With so many libraries offering JSON-serialization and REST calls, building the world’s simplest connector doesn’t take long. We ported the old PowerShell script to C# and added 30 lines of code. With the removal of file creation code we actually reduced the lines of code overall. The indexing specific part of the script looks like this:
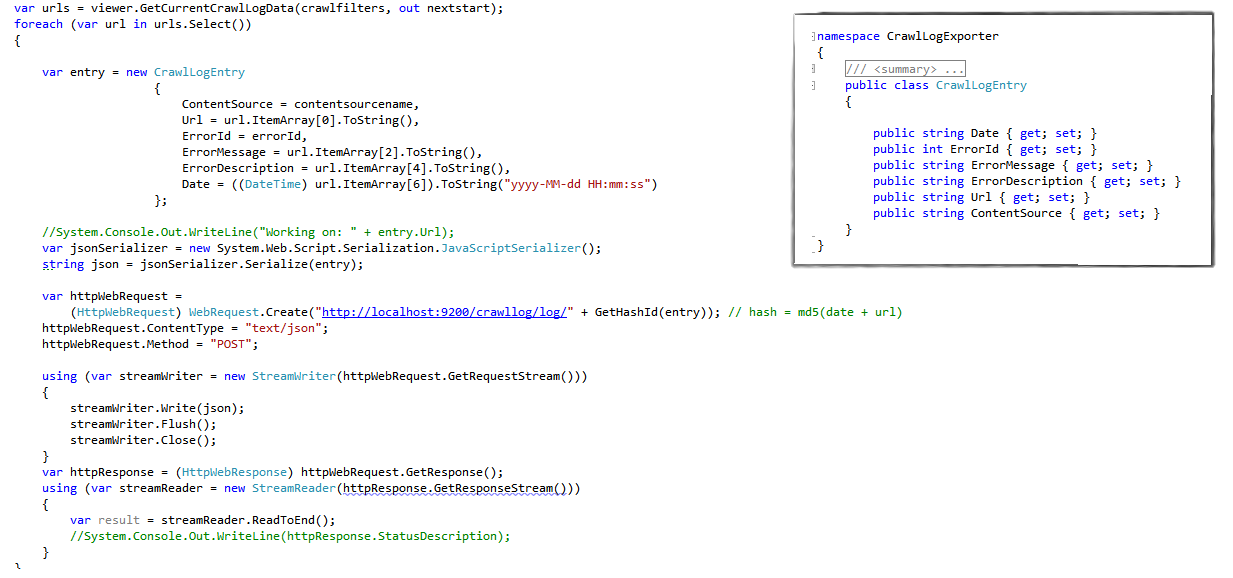
All we do is populate a little DTO, serialize it and push it to ElasticSearch. The indexing takes very little time, in fact fetching the logs from SharePoint is the slowest part of the connector. Notice that the call to index the document isn’t even done asynchronously. After indexing some data and indexing the logs ElasticSearch-head[4] is the easiest way to have a look. The tab “Structured Query” lets you create queries without any prior knowledge of the query syntax. As an example, here I have queried for all failing txt files in the log. (Some parts of the screen shot was dropped to make the image fit the page).
If you have a lot of failures in your SharePoint crawl log it makes sense to start with your most common cause of error. In the API each log entry has a property called ErrorId, although StatusCode would be a more fitting name (In PowerShell it seems to be called ErrorId and in C# MessageId). So in order to get the most common cause for errors one should look at the distribution of ErrorIds. In Fast Search for SharePoint this could be done by placing the ErrorIds in a managed property and configure it with the refiner property, effortlessly producing the distribution of ErrorIds. In ElasticSearch you specify refiners, called facets, at query time. In my limited test case the distribution looks like this:
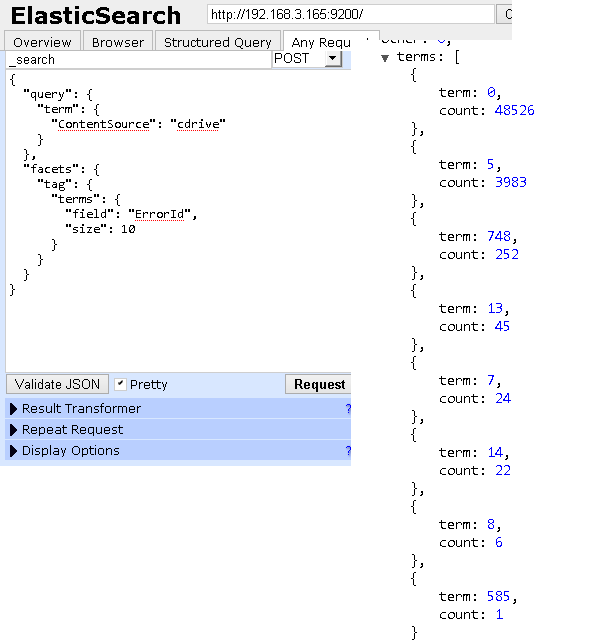
It is clear that ErrorId 0 is the most common followed by 5 and 748. What the specific ErrorIds mean is unfortunately not documented. The easiest is to query for log entries with an ErrorId and look at the error description. As mentioned ErrorId 0 means OK and 1 means deleted. All failures that happen in the Fast pipeline will be wrapped with ErrorId 11. One of the ErrorIds is simply a statement from SharePoint saying that a crawl rule was honored.
Using this as a dashboard and thinking beyond a sample crawl, you could easily envision this being a tool for checking:
- How often and when a document was crawled
- Does the crawler experience issues at certain times of the day
- What crawl rates are the crawler able to sustain in the long run
- What file suffixes are most prone to errors
- What top level folders are the most troublesome to index
The code linked below should be seen as proof of concept. You are free to download and it and it will work. Some parameters on the SharePoint API-calls can surely be set better. ElasticSearch provides a bulk-update API that should be used when indexing large datasets. If you are running ElasticSearch on a non-standard port you need to change the code. Also note the complete lack of error handling.
What about that missing file? Turns out it was there all along. The customer was searching for the filename and didn’t recognize the second hit that was displaying his document’s title, not filename. Oh well.
1: http://blogs.msdn.com/b/spses/archive/2011/06/22/exporting-sharepoint-2010-search-crawl-logs.aspx
2: http://blogs.msdn.com/b/russmax/archive/2012/01/28/sharepoint-powershell-script-series-part-5-exporting-the-crawl-log-to-a-csv-file.aspx
3: http://msdn.microsoft.com/en-us/library/ms514229.aspx
4: http://mobz.github.com/elasticsearch-head
5: http://www.elasticsearch.org
The script can be found here: Program.cs
Related Posts
 How to “spy” the data in a custom pipeline extensibility stage with FS4SP
How to “spy” the data in a custom pipeline extensibility stage with FS4SP Dynamic search ranking using Elasticsearch, Neo4j and Piwik
Dynamic search ranking using Elasticsearch, Neo4j and Piwik Hard Job Keeping Search Technology in Norway
Hard Job Keeping Search Technology in Norway 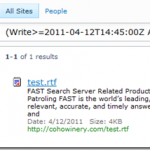 DateTime resolution for querying FAST for SharePoint
DateTime resolution for querying FAST for SharePoint- Document Thumbnails and PowerPoint Preview for your search results without installing FAST for SharePoint
- Query Suggestions in FAST Search for SharePoint 2010 (FS4SP)

