Property Extraction in FS4SP
Property extraction (previously called entity extraction in FAST ESP) is a process that extracts information from the visible textual content of an item and stores that information as additional crawled properties for the document.
In this blog post I will show how this can be automated in any given FAST Search for SharePoint installation. But first, just a short introduction to the extractors that we have out of the box:
- Companies – extracts company names based on a generic dictionary.
- Locations – extracts names of geographical locations based on a generic dictionary.
- Person names – extracts names of persons based on a generic dictionary.
In most cases, you will have companies, locations and person names that are specific to your company or organization. However, you may want to modify the built-in property extractors by adding inclusion lists and exclusion lists to improve the quality of these extractors. Typically you can use customer lists from your CRM system, employee information from your ERP system, and product listings you might have.
In order to accomplish this in an easy manner, we need some PowerShell magic.
First, just a quick overview of the input paramenters to the script:
|
1 |
.\PropertyExtraction.ps1 -file [fileName] -type [companies|personnames|locations] -addto [include|exclude] |
where the file parameter is the list of properties to extract, the type parameter specifies which property we’re dealing with and the addto parameter sets if the properties will be added to the include list or the exclude list.
Below is a snippet of where the fun takes place in code.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
function ImportEntities() { #Setting term entity dictionary to be "companies", "locations" or "personnames" $entityExtractorContext = New-Object -TypeName Microsoft.SharePoint.Search.Extended.Administration.EntityExtractorContext $entityExtractors = $entityExtractorContext.TermEntityExtractors foreach ($extractor in $entityExtractors) { if ($extractor.Name -eq $type) { $entityExtractor = $extractor log VERBOSE "Setting extractor to: $type" } } log VERBOSE "Reading file: $file" try{ $input = Get-Content $file } catch{ log ERROR "Failed to read file: $file"} #Iterating over properties dictionary and adding them if they haven't been added before $input = Get-Content $file foreach($entity in $input) { if ($addto -eq "include") { if ( $entityExtractor.Inclusions.Contains($entity) ) { log WARNING "Entity already added ($type): $entity" continue } else { try { $entityExtractor.Inclusions.Add($entity) log VERBOSE "Added entity ($type): $entity" } catch { log ERROR "Failed to add entity ($type): $entity" } } } elseif ($addto -eq "exclude") { if ( $entityExtractor.Exclusions.Contains($entity) ) { log WARNING "Entity already excluded ($type): $entity" continue } else { try { $entityExtractor.Exclusions.Add($entity) log VERBOSE "Excluded entity ($type): $entity" }catch { log ERROR "Failed to exclude entity ($type): $entity" } } } } log VERBOSE "Finished loading $type properties." } |
An example company list file could look like:
|
1 2 3 |
Apple Comperio Microsoft |
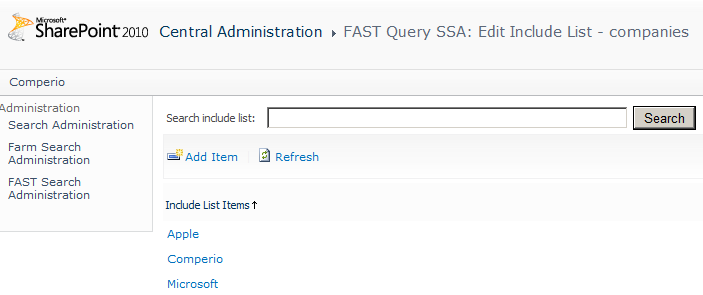
If you did a crawl before starting on your white and black lists, you can use any noise in your navigators as input to the black list, and also entities missing in the white lists. An easy way to get all navigator values is to search for “#”, which will do a blank search showing all data you have access to.
Now that you have added the new white and/or black lists, you should schedule a new crawl and the quality of the entity refiners should be improved. Voila!

Related Posts
 How to “spy” the data in a custom pipeline extensibility stage with FS4SP
How to “spy” the data in a custom pipeline extensibility stage with FS4SP Hard Job Keeping Search Technology in Norway
Hard Job Keeping Search Technology in Norway  Increasing the summary length in FS4SP
Increasing the summary length in FS4SP How To: Debug and log FAST Search pipeline extensibility stages in Visual Studio
How To: Debug and log FAST Search pipeline extensibility stages in Visual Studio Dynamic search ranking using Elasticsearch, Neo4j and Piwik
Dynamic search ranking using Elasticsearch, Neo4j and Piwik XSLT creation revisited for SharePoint 2010 Search and a small search tip
XSLT creation revisited for SharePoint 2010 Search and a small search tip

Great article – In addition to the out of the box extractors I have used the custom extractor Wholewords1 where you can build your own dictionary from scratch. Compared to the out of the box extractors I found a least one big disadvantage using a custom extractor. When you for example have two dictionary entries (key, value) Wine,Wine and Chardonnay,Chardonay and you use both keys in a document, you only get a refiner values for one of the values which in my opinion makes it useless for searching. I know that dictionary keys are case sensitive and ensured to have an exactly match in my document.
I have tried to add some new keys to the Person names extractor and it works fine with multiple key values in a document.
Do you have any experience with custom extractors and do you know how to get around the problem described above?
Steen, make sure the managed property where you map your wholeword crawled properties have MergeCrawledProperties = true. If not you will only get one value.
Thanks for the comment, Steen. Please let me know if Mikael’s approach doesn’t work. I might just have another trick up my sleeve.
Thanks Mikael, with MergeCrawledProperties = true it works fine. It is a little bit confusing that MergeCrawledProperties is called “Include values from all crawled properties mapped” in the GUI when you only want to map to one crawled property.
I agree that it’s not an easy find. But if you read the remarks on TechNet it says: This property must also be set to [true] to include all values from a multi-valued crawled property. If set to [false] it would only include the first value from a multi-valued crawled property.
I learned it myself by looking at the config for location and people managed props, not by reading the docs ;)
It’s a little bit tricky to see whether a crawled property is multi-valued as the multi-valued field in the GUI is set to false even the property has a multi-valued value. Looking at the CrawledProperty Class, it does not contain a multi-valued property. Retrieving a crawled property through PowerShell you can see that it has an IsMultiValued property that is read only but it is still set to false even the content is multi-valued. The safe way to see if crawled property is multi-valued is to check the content and see if it contains a separator char i.e. a 0×2029
Hi, thanks for posting! I had been using dictionary extractors with custom people and locations lists, this is great.
I did run across a strange behaviour, though, when I try to have a refiner for a property mapped to wholewordsx on the same refinement panel as one mapped to a pipeline extensiblity extracted property. It seems unbelievable but I reproduced it in two completely different environments. I can have my three refiners mapped to the wholewords dictionary extractors OR I can have my 6 refiners mapped to custom properties extracted with an extensibility component. The data is there in both cases, and it fails if I have just one of each kind.
Just wondering if you’ve seen anything like that?
Many thanks,
John.