Crawl interfaces for Forage running inside your browser
Got an idea a while back on how we could use the JavaScript/Nodejs Search Engine Forage so that the users would have their own search server inside the browser. The main takeaway from this would be that you don’t need to install anything to test the search engine. Since last time, I’ve made a quick logo for Forage, and drawn some more user interfaces. The mockups are mainly about crawl interfaces setting up the crawler, which in Forage terms is called Forage Fetch.
Crawl interfaces, suggested
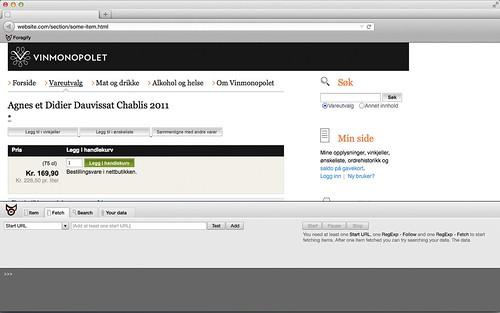
To crawl most pages elegantly and easily, you need five information elements:
- Somewhere to start. Which place do you want your crawler to start. You don’t have to specify the domain, we pick the domain name from the page you’re visiting.
- Which links to follow. This is not necessarily the pages you want to crawl. Typically these pages have lists of pages you want to crawl.
- Which links not to follow. To not make the crawler go wild, you set some boundaries. Often a page has several URLs.
- Which links to crawl. These are the actual pages you’re looking for.
- Which links not to crawl.
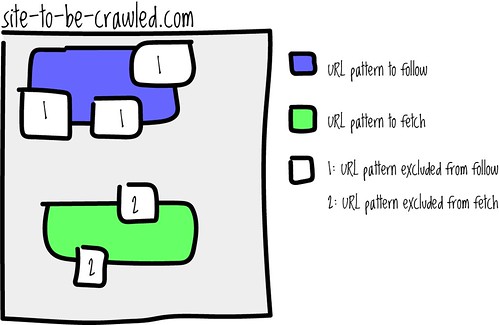
A simple illustration on the above rules. Forage Fetch doesn’t have all these features yet, but they’re suggested as enhancements.
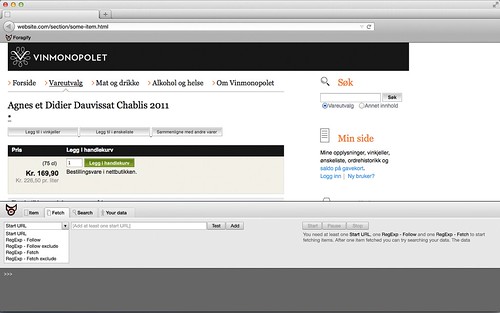
Selecting which rule type to add
To ensure you’re adding valid rules, it’s a good ting to test first.
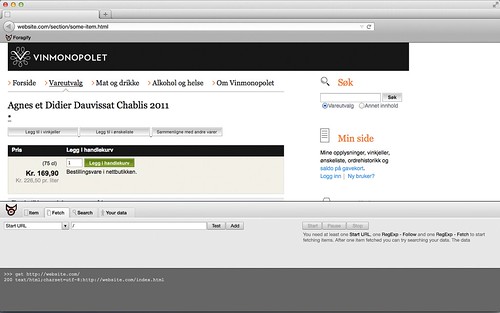
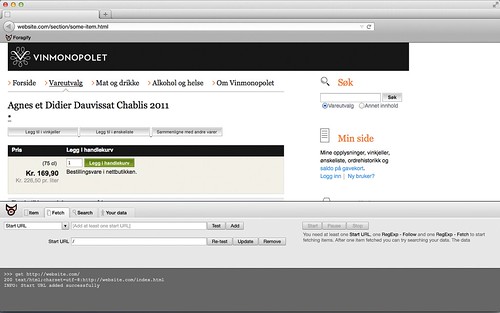
The minimum amount of rules needed to start the crawler
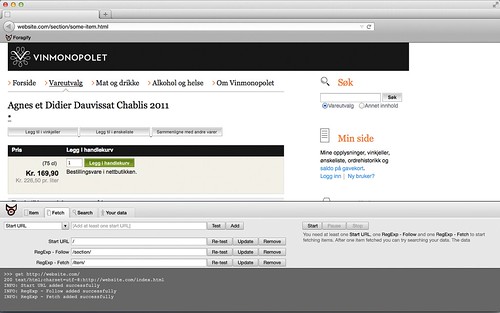
Next tasks will be to make a clickable prototype in HTML/CSS and read up on HTML5 local storage/web storage.
All comments on the idea are welcome! Here’s what we’ve blogged about Forage so far.
Related Posts
 5 reasons Lebron is the future, or why the Forage search engine will rock
5 reasons Lebron is the future, or why the Forage search engine will rock Idea: search server running inside browser
Idea: search server running inside browser Idea: Your life searchable through Norch – NOde seaRCH, IFTTT and Google Drive
Idea: Your life searchable through Norch – NOde seaRCH, IFTTT and Google Drive Norch is changing its name to Forage
Norch is changing its name to Forage Main navigation for recipe app user interface ready
Main navigation for recipe app user interface ready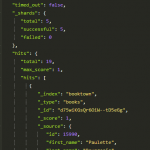 Elasticsearch: Indexing SQL databases. The easy way.
Elasticsearch: Indexing SQL databases. The easy way.


[...] Posted earlier on Search Nuggets. [...]